Contextuals are formatted like this (hover over me)congratulations!, and offer small bits of context around phrasing or word use.
Hovertips are formatted like this (hover over me)$S$Quantum electrodynamic action functional $= \displaystyle\int \psi^\dagger \gamma^0(i$$\gamma^\mu$Dirac matrices$D_\mu$gauge covariant derivative$- m)\psi$ $\displaystyle-\frac{1}{4}$$\displaystyle F^{\mu\nu}$electromagnetic field tensor$\displaystyle F_{\mu\nu}\ d^4x $, and offer media elements or small bits of extraneous information.
Linked TOC
The Structure of Optimization
Version 0.1, posted Nov 27 2023 by Mariven
This essay is worth reading for those who suspect that some fundamental changes to the way we think about problem-solving in general must happen in order for us to understand how the artificial intelligences of the near-future will solve the problems they're given, and to figure out how to robustly control the ways in which they solve problems so that their actions stay consistent with our values. To this end, I'm going to sketch out a cognitive framework with which to think about problem-solving in general, and which I believe is capable of helping us solve the problem of understanding problem solvers.
Introduction
geometry is a language for thought
In essence, what I'm trying to do here is link the theory of behavior, which splits into theories of inference (resp. modeling, perception, sensation) and optimization (resp. control, action, motion), with the theory of geometry. Throughout human history, geometry—the study of spatially extended objects—has served as not just a tool for thought but an entire language in which to think, a bed on which to intuitively present formalisms which would otherwise lie beyond our reach:
The axiomatic methodology of modern mathematics originates with Euclid's proof-based approach to geometry, and is still commonly taught via proof-based geometry;
Descartes used coordinate systems to bring geometric intuition to algebra and algebraic rigor to geometry;
Newton not only invented calculus via geometric arguments and diagrams, but created his entire system of classical mechanics using the tools of Euclidean geometry
Most of Newton's Principia represents physical laws via ruler-and-compass diagrams, rather than through coordinate systems as is done today — it's an interesting counterpoint conceptually, though an incredibly boring read.
.
Faraday used "lines of force", now called field lines, as a visual device for reasoning about electromagnetism; though he knew only basic algebra, he was able to geometrically reason about many of the laws that would later be formalized by Maxwell.
What I'm trying to do here is add another point to this list, by showing how the formal study of behavior—that is, the theories of inference (modeling, perception, sensation) and optimization (control, action, motion)—can be reconceptualized as fundamentally geometric. The main point of contact between the two is the notion of a configuration space, which translates spatial extension into differential determination. When this metaphor is generalized in line with the fundamental formalisms of statistical physics, so many powerful approaches, deep questions, and fundamental insights fall right out of the resulting geometric approach to inference and optimization. In particular, I'll demonstrate a method for identifying instrumental values in arbitrary optimizing systems, using geometric intuition to immediately understand why and how they arise from prima facie unrelated goals.
It's useful to have a background knowledge of many areas of math and physics, especially Bayesian inference, statistical and quantum mechanics, and differential geometry; though, if you've never encountered the notion of a configuration (or state, sometimes phase
(some fields of physics draw a clear distinction between state space and phase space, but it's not relevant here)
) space, or if notions like 'conceptspace', 'mindspace', and so on have never come naturally to you, you'll have to leap across some large inferential gaps.
breakdown of parts
Parts A and B introduce the "worldspace" metaphor and show you how to use it to turn your basic physical intuitions about space and movement into propositions about intelligent agents. Part C derives several basic instrumental values through this method, and shows how they can make intelligent agents inherently threatening. Part D concretizes this, building a threat model that describes many 'generic' ways in which AI can lead to ruin in the next few decades. Part E is a supplementary deconstruction of the notions of intelligence and agency via comparison to biological systems, and demonstration of how to rebuild them as tools rather than shackles via comparison to the mathematical treatment of "space". This might seem overly philosophical, but I'm really just trying to be mindful of how we conduct our thoughts, since almost all seemingly insoluble problems arise from the most basic and "natural"-seeming consequences of our conceptual frameworks (see e.g. mostparadoxesinmathematicsandphilosophy)—they're illusions that we create for ourselves, and get trapped by until we stop looking at the problems themselves and look at the way we look at the problems. When constructing new cognitive frameworks, new ways of looking at things, it's best to figure out how they work as soon as possible, so as to detect and correct for their inherent flaws.
how to readHow to read: Left-hand annotations indicate the import of certain paragraphs—the specific concept being introduced, point being argued, etc., and contain paragraph numbers (displayed on hover) to make referencing easier. Footnotes, which are formatted like [5], contain often important extensions to the main text; sidenotes, formatted like e, contain first-order corrections, specifications, and other asides; leads, formatted like Q5, ask questions that point to worthwhile future investigations. Extra notes, hidden by default but formatted like [C], are for digressions that get really into some less-than-relevant weeds. Mouse over green text to see information related to that text—this allows me to do cool stuff like this: $R_{\mu\nu}$Ricci curvature $R_{\mu\nu}=R^{\sigma}_{\mu\sigma\nu}$$-\frac12$$R$Scalar curvature $R=R_{\mu\nu}g^{\mu\nu}$$g_{\mu\nu}$spacetime metric$=$$\kappa$Einstein's constant $\kappa=8\pi Gc^{-4}\approx 2$e$-43\ \operatorname{N}^{-1}$$T_{\mu\nu}$stress-energy tensor $T_{\mu\nu}=-2(-\det g)^{-1/2}\left(\delta S/\delta g^{\mu\nu}\right)$..
Note: This document was welded together from research notes and illustrative sketches
(Unless other specified, all images were created by me)
, and I haven't had time to rewrite it in simpler, more consistent language. It will be cumulatively updated with additional material over time if there seems to be any point to doing so publicly—hence the version number. Right now, the main body doesn't extend beyond the beginning of part C, but some images, notes, and resources are attached afterwards as a demonstration of the kind of material that I am privately working on.
A. Navigating World States
To human conceptual cognition, the world we find ourselves in has a single actual state, and many ways in which it could possibly be different
The notion of a 'possible world' is fictional—everything that is, is because of a chain of prior events that not just caused but necessitated it. (The Many Worlds Interpretation doesn't violate this so much as expand it). But concepts are fictional in general, and thinking of possible worlds is often a useful way of reorganizing these fictions.
. The current state of our world represents a single point in this ocean of possible worlds, and individual dimensions of this space are particular ways in which the world can be different. As I type this, for instance, the point representing our world oscillates rises and falls along several dimensions in succession, as the keys on my keyboard rapidly change their elevations—being a part of the world, any change to them induces a change to the world. Each of the individual plastic molecules is a part of its key as well, and as these are steadily shaken up and scraped off, the state of the keyboard slowly and chaotically drifts in a ridiculously large number of dimensions. But to consider the state of every molecule in a macroscopic system would overcomplicate any realistic model of that system without adding anything useful; we have to pick a useful level of detail to work at, a sort of threat model which tells us the kinds of correlations of movements we're interested in.
concepts of worldspace and worldstate
In the case where we're limiting that part of the world under our consideration to just the (say 56-key) keyboard, we might consider that while the zillion constituent molecules are always moving around on their own, there are 56 different kinds of large, correlated movements of molecules (corresponding to individual keys that might be pressed), making the space of states essentially 56-dimensional if we blur our eyes
In case it doesn't go without saying, you shouldn't try to visualize all 56 dimensions. If you want to visualize how some particular movement or group of positions in this space might look, limit yourself to that which can be visualized using only a two or three-dimensional slice of the space. The illustrations below will be 3-dimensional at most, and yet the qualitative features they illustrate generally apply well to higher-dimensional spaces as well. All you have to do is identify these features, and then extrapolate them—"imagine $n$-dimensional space, and then just set $n=56$". Nevertheless, there are some strange features that only appear in high-dimensional spaces—mostly concerning distances and angles—which will be mentioned when relevant.
.
We say that the vastly larger, more accurate space is fine-grained, while the simpler space obtained by making some conceptual simplification is coarse-grained. Almost always, we'll take a the coarse-grained view, in which we only care about those collection of patterns of change which are relevant to our analysis of some particular problem. In any case, if you imagine the space of possible worlds as a single plane, the conceptual nature of this plane remains the same: distinct points on it will correspond to tangibly different 'states', a displacement vector is an alteration of state, a path from one point to another is a continuous change that effects some alteration, and so on. This plane is the worldspace
Why not just call it "the state space"? First, because there are many different constructions of state spaces for different conceptual purposes, and we'll mix some of them later on; it's useful to keep the concept of worldspace (not "a" worldspace) distinguished. In any case, much, but not all, of the discussion of worldspace will generalize to other state spaces. Second, and more importantly, worldspace does not just refer to a conceived space, but to an entire conceptive framework for understanding the local and global structures of this space, and therefore for predicting how goal satisficing and (more generally) optimization will lead to specific patterns in the world.
,
and any single point on it a worldstate.
In statistical mechanics
,
we'd call the fine-grained version of this structure the configuration space, and its points microstates. Two points might be different as states by virtue of the tiniest shift in the position of a single atom—in other words, the identity of a point tells you everything about that world down to the micro-scopic scale
In fact, quantum (quantized) mechanics tells us that we can take the microstates to be discrete/countable rather than continuous/uncountable, and, in a bounded system, to just be finite (but enormous). This is the approach that e.g. Pathria's book on statistical mechanics takes, giving the resulting theory a crisp combinatorial flavor. But, whenever possible, I'll stay away from picking between discrete and continuous, or between finite, countable, and uncountable, since the qualitative behavior of operations on state space is often independent of these features
For instance, you might expect the time evolution of a certain continuous region of state space to be able to expand its volume $V$, while being unable to expand a set of $N$ discrete microstates into $N+1$... but usually we're only interested in this volume insofar as it possesses a probability density $\rho$ and therefore a measure $\int_X \rho\,dV$; several theorems, many of them called Liouville's theorem, tell us that time evolution conserves this measure, which generally allows us to think of continuous measure and discrete numerosity in the same way.
.
I also haven't fully specified what exactly a microstate consists of: "state space" and "configuration space" are usually used to indicate that a microstate specifies the precise position of every atom, while a microstate of a "phase space" usually specifies position and momentum. Again, though, this will largely be irrelevant.
.
Our coarse-graining procedure quotients flattens this microscopic information by computing some very lossy function of it that we actually care to think in terms of. For instance, if you're drinking a cup of coffee, it never crosses your mind to ask what this or that particular atom in the cup is currently doing; instead, you care about things such as the temperature of the coffee and whether the cup is full or not. Even though these coarse-grained features supervene on the exact atomic details—you can't make a cup of coffee full or hot except by changing these details—they do so in a stable, smooth, and predictable manner that prevents us from having to worry about whether e.g. some atom might suddenly accelerate to $0.99995c$ or fill up the entire cup by itself. There are so many particular arrangements of atoms that could yield a full cup of coffee at 120°F, but we don't want to control each and every atom, we just want hot coffee. In statistical physics, these coarse-grained, macroscopic state specifications are called macrostates.
coarse-graining is a necessary error
If you want to object to the existence of some discrete set of valuesi.e., any particular coordinate system such as {is hot, is full}, or at least to our ability to find some quantitative algorithm for figuring out how to delineate them in a way that exactly matches our wishes... you'd essentially be correct to do so. The assumption of a set of such values, which is implicit in our coarse-graining, will come back to bite us. But working with microstates directly is just not possible—treating every one of the $\approx 10^{25}$ molecules
1 cup coffee $\approx$ $250 \operatorname{cm}^3$volume in a quarter liter $\approx$ 1 cup $\times$ $1 \frac{\operatorname{g}}{\operatorname{cm}^3}$density of water $\times$ $(16+1+1)^{-1} \frac{\operatorname{mol}}{\operatorname{g}}$(inverted) atomic weight of water $\times$ $(6\times 10^{23} \frac{\operatorname{molecules}}{\operatorname{mol}})$Avogadro's number $= \frac{250}{3}\times 10^{23} \approx 10^{25}$ molecules
as something to add kinetic energy to separately from the rest is both ridiculous and practically impossible. Our conceptual approximations are our undoing, but we'd be immobile without them—this is an unsolvable problem, and the only way around it is constant vigilance. "The" space of macrostates is a convenient fiction, a conceptual fabrication that would be entirely foreign in nature to what it is now had a few of the unconscious intuitive choices we constantly make gone slightly differently. It's only a tool through which we can use our spatial-kinesthetic-geometric intuition to think about intelligence
This is the reason I'm adamant on making the figures 3D, even though it takes me five times as long—it allows us to get the most out of these intuitions.
.
I've gone to great lengths to integrate this tool with the actual formalisms of statistical mechanics, since it integrates very naturally and effectively with these formalisms, but, if you find this unhelpful, it's better that you not pay attention to my speaking of microstates, macrostates, and entropy; the cognitive framework takes us very far even if we use it naively, because it has a strange sort of ideatic ability to transcend the limitations of any one mind
In fact, my use of the worldspace formalism to derive results on instrumentality came before my realization that statistical mechanics was such a useful way of grounding it in the kind of mind-independent-coherence that's needed to resolve the forever-wars cognition keeps getting dragged into on account of its searching for the truth of things even though it is not of the right form to cognize such truth.
A second thing evincing this transcendence is that I could've just as well provided such a grounding using the entirely different language of differential geometry, speaking of tensor fields, coordinate-independence, and holonomy rather than microstates, entropy, and ensembles. Pseudoriemannian geometry is already built to articulate the nature of the ortho-spatial expansiveness that we call time, and we could get a lot of mileage out of treating worldspace using geometric results from mathematics and physics (geodesics, Fermat-type and more generally variational principles, blah blah blah). This'd give us a new way of looking at the situation that could produce the same results as we obtain from the point of view of statistical mechanics but in all likelihood would end up showing us an entirely different perspective. I do intend to discuss how all of this applies to worldspace in a future essay, since the novelty of the perspectives thereby provided does obtain, rendering it very useful. E.g., many times throughout this essay I'll talk about the "topography" of worldspace, and that isn't nearly as easy to conceptualize in the language of statistical mechanics as it is in the language of differential geometry.
Much later on, I'll explore what it is about reality, and about us, that should let such a conceptual structure like worldspace "participate" in the kind of transcendence that lets us use it to think about reality at all. If by the time you manage to reach that part this new level of abstraction makes you want to puke, feel free to do so. You've earned it.
.
outcome pumps and edge cases
C.f. The Hidden Complexity of Wishes—the non-alignment of the genie therein is essentially a consequence of the facts that (a) there are a massive amount of microstates corresponding to a single macrostate, (b) it is extremely hard to demarcate beforehand the space of said microstates, since there's some level of micro-level specificity at which you just have to wave your hands and say "I don't know, that's kind of a weird edge-case...", and (c) the edge-case-space grows larger with the number of relevant macro-level factors
In high-dimensional spaces, shapes tend to be "shallow". We can demonstrate this by doing the thing every machine learning book does—demonstrating the unintuitive properties of these spaces by studying their spheres. The volume of a ball of radius $r$ and dimension $D$ is given by an equation of the form $V(r,D)=r^Df(D)$, so the proportion of points of the unit $D$-ball within a small positive distance $x$ of its boundary is $p(x,D)=1-\frac{(1-x)^Df(D)}{1^Df(D)} = 1-(1-x)^{D}$.
Geometrically, this is how much of the ball lies within the outer shell of thickness $x$; probabilistically, it represents the chance that any random point sampled from the ball will turn out to be an edge case—we can think of it as a danger zone, and $x$ as a parameter controlling the size of the danger zone, a.k.a. our vulnerability. In this latter sense, it's clear that we want to keep this probability as small as possible. Usually we think to prevent $x$ from rising by making ourselves stronger or safetyproofing the environment—but an increase in $D$ will elevate the probability just the same! (For $y=-\ln(1-x)$, which is near-identical to small $x$, $\frac{\delta p}{\delta \ln y} =\frac{\delta p}{\delta \ln D}$, so that a small multiplicative change has the ~same effect when applied to either $D$ or a small $x$).
To put it in other words, points in a high-dimensional sphere get arbitrarily close to the edge as the dimensionality increases. This is tricky to intuit geometrically, but perfectly clear logically: to be close to the center, you have to be close on every single axis—in this way, closeness is a $\forall$ proposition—whereas being close to the edge requires you to be close on just one axis—non-closeness is a $\exists$ proposition. The more axes there are, the more ways there are for things to go wrong; a single fatal coordinate in an array of safe coordinates renders the entire vector fatal. In the context of safety, we're playing on the $\forall$ team, and the enemy is playing on the $\exists$ team. When the set of potential vulnerabilities is large, $\exists$ wins by default.
,
of which there are always many more than you think.
finite paranoia is insufficient
In the context of that piece, we might, for simplicity, imagine a criterion like "my mother should be in a safe place outside of that burning building" as being discretized into three macrostates (safe, in danger, roasting), but the underlying reality actually admits an ocean of microstates, many of which straddle borders between macrostates in ways that never even occurred to us. In most of the possible relocations from inside to outside, something goes wrong that you never even imagined would go wrong: there are millions of axes along which things can go wrong, whereas your limited imagination only leads you to cognize two, three—maybe fifteen if you're absurdly paranoid—of these axes.
When your coarse-graining fails to align with your exact interests, things don't go how you imagine they will. Red (fatal) seems straightforward to avoid, but when considering how to move from unsafe (yellow) to safe (green), a predetermined solution is far more likely to fail than a continuous process of monitoring and control.
Paths as Solutions
plotting paths through worldspace
If you take an agent, imprint on it some particular goal
For brevity, we'll abbreviate such an Agent with Goal Imprinted as an "AGI". What exactly is meant by "agent" doesn't particularly matter yet—just imagine some being that freely acts on the world in order to achieve some goal.
,
and give it the capacity to modify the world, it will start modifying the world in pursuit of that goal. This is the implication of an entity's being an "agent". We can picture it as attempting to get from one point in worldspace to another point where this goal is satisfied; controlling for the rest of the world, it will trace a path from this world to some goal world, this path characterizing the exact approach the agent took to achieve the goal. Plot time on the z-axis against the world-state on the x-y plane, and you'll get a graphical representation of this approach:
(you're looking down on the cube from above)
goal-based vs utility-based navigation
The yellow point is not the goal; there are many different worlds that instantiate the goal, or which in any case the agent is indifferent between, and the yellow point just represents a single such world. Let's suppose that the green square is the collection of all worlds in which the goal is achieved, hence the yellow point's lying on it. (Why aren't we formulating this in terms of utility? See:
Truthfully, we could just as well have deployed the concept of a utility function $u$ over worldspace ${\cal W}$ in lieu of a set ${\cal G}$ of goal worlds. This would be more general, since any such set can be replaced with its characteristic utility function $\chi_{\cal G}(w) =$$[w \in {\cal G}]$(Iverson bracket). It's also more flexible: we might choose $u$ to be time-independent, or time-dependent in a known or perhaps merely inferrable way. We might choose it to be a function of the entire path $p$$p(t_0)=$ starting world $w_0$, $p(t)=w$$: [$$t_0$starting time$,$$t$current time$] \to $ ${\mathcal W}$worldspace taken to get to the state
That is, the "function" is perhaps some more complicated sort of equipment, e.g. a functionaloperation sending paths to scalars, e.g. $I[p] := \int_{0}^T ||\dot p(t)||^2\,dt$. Two natural families of cases in which we could expect such things are (a) utility functionals which depend on the shape of the path (e.g., we tell SurgeonBot not to proceed too rapidly, so if it screws up we can react quickly enough to override it), and (b) utility functionals which value certain transient, vanishing things (e.g., NurseBot cares for the terminally ill, and sees utility in comforting them today even though they'll be dead all the same tomorrow).
, like $U[p] = \int_{t_0}^t L(p(\tau), \dot p(\tau), \tau)\,d\tau$ or merely a function of any particular world, like $U[p]=u(p(t))=u(w)$
The first class consists of the utility functions, or maps from ${\cal W}$ into a poset, which for whatever reason we choose to be ${\mathbb R}$. The second class consists of the utility functionals, or maps that take maps $[t_0, t] \to {\cal W}$ to elements of ${\mathbb R}$ again. If we call the former ${\cal U_1}$ and the latter ${\cal U_2}$, we have a canonical injection $\iota: {\cal U_1}\to{\cal U_2}$ with $\iota(u)[p] = u(p(t))$. A functional evaluates a present time and its history, so "get the current value of this" is an operation that turns functions into functionals. So ${\cal U_2}$ is really an enlargement of ${\cal U_1}$ given by allowing utility functions operators to take history into account. Are there further enlargements, whether in the form of a string of inclusions ${\cal U_2}\subset{\cal U_3}\subset{\cal U_4}\subset\ldots$ (or some more general posetal structure), or are we all out of features to take into account? I see a couple of contenders for what ${\cal U_2}$ could be, but I feel like there should be a good and retrospectively obvious answer which naturally suggests a family of further enlargements that end up encompassing these contenders.
Abram Demski discusses similar issues in An Orthodox Case Against Utility Functions, asking: what is a utility function a utility function of? AD goes on to outline an approach to utility that ditches entirely the notion that utility need be a function of a world: a toy theory using the decision-theoretic Jeffrey-Bolker axioms sketches a notion of utility which just depends on events, with a "world" merely being an event that describes an entire world-state
AD makes a very interesting analogy: if reasoning about (fine-grained) worldspace is like ordinary topology, reasoning about events is like locale theory (pointless topology).
.
That I speak not only in terms of an explicitly coarse-grained worldspace but in terms of reasoning about the "topography" of this space means that I can't update much from the arguments it makes, since I've kind of taken an orthogonal path to a parallel conclusion, but it's a very interesting way of thinking about the underlying ontologies of utility functions.
NurseBot seems like an important example. When utility is solely a function of worldstate, "all's well that ends well", but suffering seems intrinsically bound to changes of worldstate: if you shoot someone in the leg, deep-freeze them two seconds later, keep them that way for ten years, restore their leg to its original state, and then unfreeze them immediately afterwards, their subjective experience will be like a sharp flash of pain that disappeared as quickly as it came, right? given that the actual physical activity which consciousness arises from, or at least couples to, has been stopped? In other words, suffering seems to be inherently time-dependent, so that treating of it requires picking out points not in worldspace but in its path-space. What other reasonably-natural utility function correlate
"Suffering" can never be a utility function in itself or even an input to one; a utility function can only ever depend on suffering by treating of its inputs by structuring them in a manner homomorphic to the manner in which actual suffering arises from them, i.e. by depending on a constructed image of suffering. Hence, correlate. I guess in many cases this particular one would be a proxy as well, since suffering is something humans want to alleviate in themselves and cause in others, but we'll stick with the more general 'correlate'.
satisfy this property? Are they characterized by common properties or origins? Do optimizers of this kind of utility function end up acting in common ways unique to the kind? Are there utility functions which intrinsically depend on higher-order derivatives?
.
So why not utility? Four primary reasons. First, as the length and intricacy of the above paragraph ought to indicate that, if I took the time to conceptually unpack the phenomena evident in utility-based navigation the same way I'm doing for goal-based navigation, this essay would be an order of magnitude longer and denser than it currently is. It's certainly possible, and I could have a very fun and productive couple months exploring and writing about it, but my bank account says that won't be any time soon.
Second, modulo the question of how to make and act under uncertain inferences about how the utility landscapemore commonly 'loss landscape', but same difference looks behind the "fog of war", utility-based navigation is essentially the differential analogue of goal-based navigation, and I think this analogy acts functorially for the most part, with extensive/global features of goal pursuit translating into intensive/local features of utilization. Discussing the latter requires appealing to tricky variational arguments and optimality principles that are far more opaque than their analogues in the former.
Third, what's inside the 'modulo' above is pretty complicated both for goal-based navigation and utility-based navigation. If we're at a point in worldspace where we can't simply follow our utility function to its peak—perhaps we're in a valley of equal low utility, or, worse, a peak that is clearly only local, and whose local topography does not give us any information as to where a higher peak might be—in such a case, we have to intelligently extract information from our model in order to determine where to go in just the same way that we would if we were trying to figure out how to get to a goal world.
Fourth, what we actually care about is often more easily expressed in terms of goal sets than in terms of utility functions
You exclaim "but you yourself said that goal sets could be replaced by utility functions!"—yes, with a wrapper that directly points the utility function at the goal state. That informational structure doesn't disappear just because we decide to call it something else.
,
and using the latter just shoves the process of goal operationalization under the rug.
).
Note that this isn't necessarily a time-independent set, since goals can be entangled with the flow of time in nontrivial ways. Some examples: (a) an approach to the goal "make money by trading stocks" may work at one time and not another; (b) the goal "wake me up at 8 am on Monday" is confined in time; (c) the goal "surveil the world's richest person" has a de dicto time dependenceThe time dependence is a property of the pointer "world's richest person", and (d) the goal "keep this wall painted grue" has a de re time dependenceThe time dependence is a property of the thing being pointed to. We will try to assume, though, that the coordinates of worldspace don't themselves change over time, so that a (macroscopically) static world would trace a perfectly vertical line.
characterizing paths by states at a time
Not only are there so many goal worlds to choose from, but—even if we fix a specific goal world, say the yellow point—there are so many different methods to turn this (cyan) world into that (yellow) one, so many non-intersecting paths. For simplicity, we'll distinguish different approaches via their progress at halftime, marking this intermediate world in magenta:
Inserting an intermediate sampling layer as a measurement of the path, or method, by which the goal is reached
parametrization of time is arbitrary
Just as the green square on the topmost plane represents the agent's goal, it'll be useful to think of any particular subgoal as a shape drawn on the halftime plane, covering the collection of worlds in which it is satisfied. That some approaches may achieve the subgoal at different times doesn't matter conceptually: reparametrize time to even them out. But no matter how much we reparametrize, a single point won't convey everything about the path it came from. Not only are there multiple intermediate worlds one could choose to achieve on the way to their goal, but there are multiple paths through each particular world. In each case, I've illustrated an infinitesimal proportion of the whole situation:
coarse-graining affects dynamics
If you're wondering why paths which represent the same world at the same time wouldn't just merge, given that each world contains the seeds of its own future evolution, recall that they only represent the same world on some macroscopic level, rather than having the exact same microstate. There are many such microstates corresponding to any macrostate
To be precise: given a macrostate $X$, let $\Omega(X)$ be the volume, or numberagain, trying to stay continuity-agnostic, of microstates $x$ which we identify with $X$. Then, $\ln \Omega(X)$ is proportional to the entropy of the macrostate $X$; fixing the constant of proportionality to Boltzmann's constant $k_B$$\approx 1.38 \times 10^{-23}$ joules per kelvin, this is often taken as the definition of (thermodynamic) entropy. Why the logarithm? Consider that $X$ will correspond to a space of microstates which looks like a carving from a cube with a dimension for each microstate parameter; the volume of such a carving grows to zeroth order like the product of the ranges of each microstate spanned by the macrostate (i.e., the volume of the macrostate is approximable by the volume of its bounding cube in microstate space), and a first-order correction can be made by multiplying this volume by a constant representing the compactness/density of the carving, thus correcting for 'gerrymandered' macrostates with artificially large bounding cubes. So the logarithm of this volume looks like the sum of the logarithms of the ranges of each microstate parameter compatible with the macrostate plus a (negative) constant representing the logarithm of the density of the 'carving'. The effect of this is to undo the combinatorial explosion in $\Omega(X)$ that comes with having an incredibly large number of dimensions. What is left is information-theoretic: $\ln \Omega(X)$ is proportional to the number of bits needed to specify a microstate from a macrostate, or the amount of information that the coarse-graining erases when it describes a system in microstate $x$ as being in macrostate $X$.
,
and plenty of chaos to allow worlds which are only different at the microscopic level to diverge
C.f. You Can't Predict a Game of Pinball, which demonstrates how rapidly microscopic deviations can snowball into macroscopic effects. When we identify these effects as being endogenous, we say they result from volition; when we don't, we say they result from chaos.
.
The point of the concept is to analyze choices, the existence of which is dependent on exactly the same kind of black-boxing of details on which the notion of a possible world rests. Concepts like "volition" and "possibility" are fictions that intelligent beings resort to when they can't do Solomonoff inference.
worldspace is a maelstrom
That being said, we ought not to black-box those details that choices critically depend on (only those details which choices reduce into), since the navigation of worldspace depends on how an agent responds to those choices. Worldspace isn't the homogeneous white plane I've depicted it as: to an agent present in the physical world, each point will be a maelstrom of constant change, with those who do not drag the world from point to point being dragged about by it instead. Every world-point is chaotic in its own way, and presents different affordances for, or obstacles to, change in any given direction. So, the best route from one point in worldspace to another won't have a closed-form solution, just as the path of a ladybug trying to escape a hurricane doesn't—because there is no algorithm that can be written down, trying to approximate this route is a messy craft that involves taking what you can get, hedging your bets, preserving your freedom of movement, trying to infer what options are available in other possible worlds, and all the other general hallmarks of intelligence.
geometrically intuiting intelligence
If the goal-imprinted agent introduced above (AGI, or Agent w/ Goal Imprinted) is to be successful in this craft, it will need to possess its own kind of intelligence. The concept of worldspace is a way to leverage geometric intuition in order to reason about this intelligence in terms of how it acts on the world.
turning approaches into trajectories
Seriously try, if only for a minute, to picture how progress towards a goal translates into the charting of a trajectory through worldspace. Compare it to a real-world example in order to get a feel for it—the most important thing is to have some sort of feel which translates itself into intuition. Go play, say, Street Fighter or chess, and see how your mind constructs a local 'topography' for worldspace off of which it reads the relevant considerations and salient action plans at each point in time. Discretize it if you like, with a bunch of individual points each of which contains routes to other points slightly ahead in time (recognized affordances), and equip each route with some information about its traversal such as the amount of risk incurred thereby. Like a weighted DAG. Then you can formulate scenarios such as the one below, whose narrative is as follows: an agent decides to take a risk-lowering action that makes the goal slightly more distant, under the assumption that there'll be plenty of future actions that make up for that distance while keeping risk low, but no such opportunities show up. The path-of-least-resistance it's accidentally put itself onto is one where the distance to the goal grows and the cost of correction grows even faster.
feels bad man
B. Local Pathfinding
innate dynamics of worldspace
Imagine we were habitually indisposed to consider the state of the actual world as being a point in worldspace, and to conceptualize given goals as "moving the worldstate from here to there". What would we notice as we tried to consciously move about this space—what are its dynamics?
(Chaos) The world changes even if you don't do anything to it, due to other agents and natural processes. Sometimes nations go to war; sometimes mad scientists take over the world; sometimes the sun explodes. Unless you entangle yourself in each individual situation, it'll kinda just happen. The consequence of all of this change is that navigating through worldspace isn't like walking from your bedroom to your living room, but like zooming around the Himalayas on rocket-propelled ice skates.
(Ease of Movement) At each point, it's going to be easier to move in some directions than others; these need not correlate with closeness to your goal. People modify this easiness by building structures, barricades, tripwires, and other security features on worldspace. If you want to acquire a nuclear weapon—to move to a worldstate where a nuke is in your sole possession—you have several possible methods, but all of the visible ones are very difficult to achieve, since major nations' security apparatuses form a very large, very tight barrier around the space of worlds where rogue individuals have nuclear weapons. To just pierce through requires enough power that there's no point in doing so, and finding a hole to sneak through requires incredible predictive/perceptive ability and the right initial position (or opportunity).
(Intelligence) The locally and directionally dependent ease of movement provides worldspace with a sort of topography of difficulty, or risk: it's like climbing a mountain, where some paths are easier than others, some paths are basically doomed, and some paths you can (or must) take a chance on. Now, it's very hard to see more than a couple (metaphorical) meters in front of you—plans with more than a single step routinely fail, and the option space from a certain point often looks a lot different when you're at that point rather than when you're scoping it out from afar.
Those who can see through the fog and correctly judge the topography from afar have significant advantages when it comes to moving the worldstate: their multi-step plans are more likely to work; they can plot out a wider variety of paths while minimizing risk and moving towards their goals; they can see and prepare for worldspace's chaotic undulations. Vision, then, is analogous to intelligence
People use the word "intelligence" in all sorts of subtly different ways without even realizing it, which is one reason the AI alignment problem has been so difficult—like construction workers building a skyscraper each according to their own unique blueprint. I don't want to claim that clarity of vision here is representative of a canonically universal concept of intelligence; a loose synonym for my use here might be "good judgement".
I certainly wouldn't have any idea how to use the adjective "general" to characterize this; it seems like I'd inevitably fall into so many perspective traps and accidental motte-baileys that I'd never have any useful thoughts again! Human general intelligence can loosely be interpreted as g-factor—the concept is coherent when speaking of humans since a bunch of primitives for the assessment of intelligence are given to us (we know how to provoke and interpret their movement, speech, perception, cognition, and so on). The concept of 'artificial general intelligence', on the other hand... could you imagine a parallel world where that was what "AGI" stood for? We'd be doomed! hahahahaha
.
But it's never perfect; there are always blind spots, flaws in the lens that cause systematic misperceptions or limits to it that make certain things impossible to see
It could always be the case that, say, aliens are heading for us at so close to lightspeed that we'll only have seconds to react. It's probably not the case, but there's no reason the world can't be objectively unfair. .
(Death)
To admit your physical existence as an agent is to admit the possibility of your physical destruction. No matter how good you are at steering worldspace, there are certain parts of it in which you are not alive, call them dead zones, and if you hit one of those, you won't ever steer again.
This concern is in its full generality much broader: the world will keep moving with or without you, and death simply zeroes out your ability to steer it. The world can act on you in so many other ways so as to negatively impact this ability, and you ought to avoid all such things with the proper priorities.
noise is heavy-tailed in worldspace
Now, the random bumps you get in worldspace aren't all the same, or of similar severities: their severities are better modeled as coming from a high-variance log-normal distribution
That is, the distribution of a random number whose logarithm has a Gaussian distribution; since Gaussians are what sums of lots of independent random factors tend to look like (in a manner made precise by the Central Limit Theorem), log-normal distributions are what the products of lots of independent random factors tend to look like. Think about how major disasters tend to happen—many different procedural oversights and systemic flaws coincident with with poor environmental conditions and human errors. It is because the conditioning factors of events combine disjunctively, by multiplication, that the events tend to have severity distributions that look far more log-normal than Gaussian. , owing to the way they're distributed across several orders of magnitude.
100 sorted samples from Lognormal(0,5)
In the above list, the largest value is 166x the value of the second largest, which itself is 16x the third largest
These values are from the first trial I ran, no cherrypicking, but 166 and 16 still seem to be very high values for these ratios—trying to pin down what's going on has been very spooky, since it seems that if we treat these ratios as random variables, their distributions grow very heavy tails very fast.
Adapting this MSE answer: for $N$ samples from a distribution with CDF $F(x)$, PDF $f(x)=F'(x)$, the distribution of the joint random variable given by sorting the list from smallest and largest and then taking the values at $a$ and $b$, call them $X_{(a)}$ and $X_{(b)}$, where $1\le a < b\le n$, is:
$$ f_{X_{(a)}, X_{(b)}}(x, y) = \frac{N!}{(a-1)!(b-a-1)!(N-b)!}F(x)^{a-1}(F(y)-F(x))^{b-a-1}(1-F(y))^{N-b}f(x)f(y) $$
When $b=N-i$ and $a=N-i-1$, $\frac{N!}{(N-i-2)!((N-i)-(N-i-1)-1)!(N-(N-i))!}=\frac{N!}{(N-i-2)!i!}$, so the joint distribution of the $i$th from the right and the one to the left is
$$ (i+1)(N-i-1)\binom{N}{i+i}F(x)^{N-i-2}(1-F(y))^{i}f(x)f(y) $$
For a mean zero normal distribution, with CDF $\Phi(x)$ and PDF $\frac{1}{\sigma\sqrt{2\pi}}e^{-\frac{x^2}{2\sigma^2}}$, writing $j=i+1$ (i.e., one-based indexing) yields
$$ f(x,y)=\frac{1}{2\pi\sigma^2}\binom{N}{j}((N-j)\Phi(x)^{N-j-1})(j\Phi(-y)^{j-1})e^{-\frac{x^2+y^2}{2\sigma^2}} $$
(when $y\ge x$). So the PDF of the difference between the $j$th from the right (starting at 1) and the one to its left, call it $D_j$, is $$f_{D_j}(d) = \int_{-\infty}^\infty f(y-d, y)\,dy=\frac{j(N-j)\binom{N}{j}}{2\pi\sigma^2}\int_{-\infty}^\infty\Phi(y-d)^{N-j-1}\Phi(-y)^{j-1}e^{-\frac{2y^2-2yd+d^2}{2\sigma^2}}\,dy$$
The trick: the exponential of this difference is the ratio between the $j$th largest sample from $N$ log-normal RVs and the next smallest one. $p_{e^{D_i}}(r) \frac{d}{dr}P_{e^{D_i}}(r)=\frac{d}{dr}P_{D_i}(\ln r) = \frac{1}{r}p_{D_i}(\ln r)$, so the distribution of the $j$th ratio is $$ p(r) = \frac{j(N-j)}{2\pi r\sigma^2}\binom{N}{j}\int_{-\infty}^\infty\Phi(y-\ln r)^{N-j-1}\Phi(-y)^{j-1}e^{-\frac{y^2+(y-\ln r)^2}{2\sigma^2}}\,dy$$
Given this, the expected value can be calculated as:
$$ m =\frac{j(N-j)}{2\pi \sigma^2}\binom{N}{j}\int_{-\infty}^\infty\Phi(-y)^{j-1}e^{-\frac{y^2}{2\sigma^2}} \int_1^\infty\Phi(y-\ln r)^{N-j-1}e^{-\frac{(y-\ln r)^2}{2\sigma^2}}\,dr\, dy$$
Code that calculates this integral, using a cutoff of 50,000 for $r$ and $(-20\sigma, 20\sigma)$ for $y$. from math import log, pi, exp, factorial; import scipy.integrate as integrate; import scipy.stats N, j, s = 100, 1, 5 print(factorial(N)/(factorial(N-1-j)*factorial(j-1))/(2*pi*s**2) * integrate.dblquad(lambda y, r: scipy.stats.norm.cdf(-y, scale=s)**(j-1)*exp(-y**2/(2*s**2))*scipy.stats.norm.cdf(y-log(r), scale=s)**(N-j-1)*exp(-(y-log(r))**2/(2*s**2)), 1, 50000, lambda x: -20*s, lambda x: 20*s)[0])
So a ratio of 166x in this scenario seems to be around 95th percentile (and 16x for the second ratio is 94th percentile, but we should expect the two to be correlated), but the mean ratio is around 500x, or three times higher! The numerical integral has to be carried out all the way to ratios in the millions to get an accurate value, since the mean converges very slowly...
.
Things rarely blow up, but when they do, they can get really bad. Sometimes an eyelash falls into your eye; sometimes you spill water all over your pants; sometimes you get a migraine; sometimes you break a bone in a car accident; sometimes you're diagnosed with cancer; sometimes your whole family perishes in a house fire. Each one is probably an order of magnitude worse than the last, but they all happen—and, scarily enough, the probability of each seems only to be inversely proportional to its severity; rather than going to zero as $e^{-x^2}$ like a good Gaussian, it goes to zero almost as $x^{-1}$
Any non-obnoxious distribution has to asymptotically go to zero faster than $x^{-1}$ in order to be normalized—but the log-normal tail just barely does so. Using a mean and variance of $0$ and $5^2$, the log-normal pdf is
$$p(x)=\frac{1}{5\sqrt{2\pi}}\frac{1}{x}e^{-\frac{1}{50}(\ln x)^2} \propto x^{-1{\mathbf{-\frac{\operatorname{ln}(x)}{50}}}}$$
The bold term is zero at $x=1$ and grows very slowly: for $x < e^{10} \approx 10^4$, $p(x)$ will go to zero no faster than $x^{-1.2}$, and for $x< e^{25}\approx 10^{-11}$, no faster than $x^{-1.5}$.
As an interesting note, a very similar kind of random walk is often studied in biology: the Lévy flight, whose step lengths are taken from the Pareto distribution (which definitionally has tail $p(x) \propto x^{-c}$ for some constant $c>1$). The Pareto and log-normal distributions are basically the Windows and Mac of power-law distributions—they're by far the most common, and the debate over which one to use in any given situation (apparently!) gets heated quickly.
They each have their own powerful metatheoretical justifications. The log-normal distribution is the limiting distribution of the product of many positive random variables (this is the log-domain version of the central limit theorem), and therefore tends to model quantities whose rates of change scale with the quantity itself. Meanwhile, the Pareto distribution satisfies a slightly different self-similarity criterion: 20% of the population owns 80% of the wealth, 20% of that population owns 80% of that wealth, and on and on.
In any case, the qualitative behavior of a Lévy flight is nearly indistinguishable from that of a log-normal random walk, so the nature of the discussion is unaffected by making a different choice; it seems like a general outcome of heavy-tailed noise
It seems that if you randomly scatter objects throughout space with a given density (e.g., scattering chocolate eggs across an infinite field so there's on average one per square kilometer), the search strategy that finds the objects most rapidly (on EV) is the Lévy flight. I half-suspect that this provides a means to metatheoretically explain the ubiquity of heavy-tailed random walks: perhaps the appearance of power law-distributed phenomena is a consequence of the ability of those subsystems of the world that engage in Lévy flights throughout their components of worldspace to reach us more frequently than those subsystems that don't.
Putting it like this, this anthropic hypothesis isn't that strong—nevertheless, I feel like there's something here. I just can't put the guiding intuition that makes me feel that into words just yet, but it's sort of a perspective shift on the principle of maximum entropy.
To make this clearer, let's consider the many-worlds interpretation of quantum mechanics: here, we can think of a probability density $\rho(w; t)=|\Psi(w; t)|^2$ on microstates which shifts around according to Schrödinger's equation in a fluid-like manner
It is a consequence of Schrödinger's equation that the density $\rho$ changes in accordance with the same continuity equation that fluids obey.
.
(Note: insofar as MWI is not distinguished from other interpretations in the empirical predictions arising from its anthropics, it's not a presupposition of this hypothesis, merely a useful way to imagine it. So regardless of whether one takes it to be "true" or not, it's an evocative and useful perspective to have; the justification of the maximum entropy principle below demonstrates this).
So, entropy is the (logarithmic) microstate-density of worldspace, which is why we find ourselves in high-entropy worlds—microstates are what actually obtain, what probability density actually flows between, so the fact that our experience of the world is not that of a microstate implies that it will be determined in a way that prefers those experiences that correspond to more microstates, i.e. that are of higher-entropy worlds. Now, this perspective fixes the worldspace and lets a drop of density flow on top of it, but if we fix that drop and let worldspace flow under it, what worldstates will come to it? If we let the world come to us, what will we see? Ignoring the way in which we cause the world to take on certain states—though this is only an illusion—what I'm imagining is we'll see worlds that arise from microstates that zip through worldspace, which prefers those microstates that so evolve as to perform Lévy flights throughout it. The manner in which this ought to happen is dependent on the precise coarse-graining we perform, but in a manner I'm not too sure of and wouldn't have space to treat of here anyways.
.
.
being careful about dead zones
If our AGI is serious about achieving its goal, which of course it is, it wants to avoid dead zones—unless it figures that the best method of achieving the goal involves sacrificing itself, but that's extremely atypical. If the rocket skates it's strapped into—the ceaselessly brutal chaos of the world it is subject to—were merely normal (Gaussian), the AGI would be able to avoid dead zones by looking out for and consistently moving away from them. In the diagram below, the blue dot starts at the black cross and is then pushed in random directions for distances drawn from $\operatorname{Normal}(\mu=0, \sigma=3)$; this is its location history after a million steps.
log-normal walks behave differently
But when the chaos is log-normal, things look much different, since while most pushes will be tiny, you can expect a few massive ones every so often. To illustrate just how vast a change this makes in the phenomenology of the walk, here are two random walks. Each one starts at the marked cross and takes one million steps, ending up at the blue circle. Both walks draw each step angle uniformly, but the first draws each step distance from ${\operatorname{Normal}}(\mu=0, \sigma=3)$, while the second draws from $\operatorname{Lognormal}(\mu=0,\sigma=3)$:
a normal random walk (left) vs a log-normal random walk (right)
you could die at any moment (don't turn around)
Clearly, the heavy tail of the log-normal distribution is doing a lot of work. At the left end of this distribution, the tiny pushes, which form the vast majority, again produce random walk–like behavior—but with a lot of steps, you're bound to get a few massive pushes which upend everything. A lot more like real life. Merely ambling away from death isn't a solution in log-normal chaos, because you could at any point be launched right into it. To humans, this looks like—a fatal car crash, sudden cardiac arrest, choking, aneurysm, accidental electrocution or poisoning—or one of the many other occupational hazards of daily human life which can and do kill people entirely out of the blue. The analogous situations for our AGI depend on the nature of its physical instantiation—but, on the very far end of the spectrum, a lot of them are shared with humans: solar flares, global nuclear war, nanotechnological catastrophes, the actions of present or future artificial superintelligences, and so on.
optimizing movement is often optimal
If the AGI has more control over the nature of its physical instantiation than we do with ours, e.g. if it is a program capable of rewriting itself, then, if its goal is something absurdly difficult or unbounded in scope (e.g., clone a strawberry to the cellular level, or grant my every wish), it would be optimal for the agent to spend some time optimizing its movement through worldspace
To build intuition for this, here's a puzzle: a bunch of identical solar-powered robots are competing in a 100m race. They have an initial top speed of $c$, which they reach near-instantly; by staying still and charging themselves with solar energy, they can increase this top speed by $k$ m/s per second. Now, insofar as 100m and $k$ are large compared to $c$, it's best to invest in speed by doing some charging, but doing too much charging will keep you still for too long to be able to win the race. What policy for deciding when to charge and when to move wins the race?
The insight that makes this problem trivial is to note that having two separate charging periods is inefficient—it would've been better for you to add the second charging time to your first charge, since you'd get the speed it provides that much earlier. In the diagram below, the blue bot does this to beat its counterfactual red twin, who charges twice separately.
Therefore, the best strategy is to charge for $t$ seconds at the very beginning and then just run for $\frac{100}{c+kt}$ more. The total time $T(t)=t+\frac{100}{c+kt}$ seconds is minimized when $\frac{dT}{dt} = 1- k\frac{100}{(c+kt)^2}=0$, i.e. when $t=\frac{10\sqrt{k}-c}{k}$.
For instance, if the robots start off with no energy, $c=0$ m/s, and gain energy at $k=4$ (m/s)/s, the optimal strategy is to charge for five seconds and then run for five more. But if the robots start off at a refreshing $10^{3}$ m/s, $k$ has to be above $10^4$ (m/s)/s for charging to be worth it at all.
This scenario illustrates some meaningful possibilities for the action of a competent AGI given a sufficiently large goal: first, that it might through simple reasoning figure out the general structure of a near-optimal plan very early on, and, rather than continually self-improving for the purpose of hunting wider and wider, it may self-improve to fine-tune and better execute this path. Second, and more salient, is the point that optimal plans will generically start conducting self-improvement as early as possible. It is a task that, by letting one perform all future tasks faster and better, merits prioritization above all other tasks that aren't explicitly prioritized
There are multiple reasons why a given task might be prioritized: it might be a temporary opportunity (profiting off a mispriced stock), might have a deadline (defusing a bomb), might become more difficult later (preventing a pandemic), and so on.
.
.
What does this involve?
In a word...
Instrumentality
instrumental behaviors
Instrumental behaviors are convergent action patterns underlying almost all object-level goals, just as "staying alive" is a prerequisite to almost any particular thing you might want to do in life. We might also explain them as "underlying the generic object-level goal", as explained in footnote
In set theory, a property $P$ holds for almost all elements in an infinite set $S$ when the set of points where it doesn't happen has a strictly lower cardinality: most obviously, almost all reals are irrational, since $|{\mathbb R}-{\mathbb Q}| = 2^{\aleph_0}$ > $\aleph_0 = |\mathbb Q|$. In probability theory, the word 'almost' is used in a similar way, with an event happening almost surely if it happens with probability 1 but not with a priori necessity: consider picking a random point on the circle and getting the exact center. It's impossible de facto, but not de jure. The same-ish concept shows up in many different guises: a set might be negligible or meager or measure 0, or, alternately, codimension 0 or a dense neighborhood.
These are different definitions applying to different kinds of objects, but they get at the same intuition: when applied to a property, we say that that property generically holds, in a way such that counterexamples are generally sought out for their being counterexamples
e.g., in topology, path-connected spaces aren't locally path-connected, but the classic counterexamples, like the Warsaw Circle, were clearly constructed to prove a point.
.
People generically aren't (professional) violinists—if you want to show me one, you can't just call your uncle or go outside and wave to one, you have to effortfully hunt one down (and, if you can call someone you know, it'll clearly be unusual happenstance rather than commonplace). It's a stronger statement than "people generally aren't violinists", as it makes a claim about typicality, a weaker statement than "like three people are violinists", since it allows for both specific and general classes of counterexamples, and conceptually sharper than either. Humans generically gain immunity after viral infection, generically die if they fall ten stories, generically speak a language.
That intuition of genericity, of artifice being required to produce counterexamples, is what I mean by "staying alive is independent of almost any particular life goal." Q.v. also the definition given here in Every Canvas a Mirror.
Instrumental correlates hold generically for control-complete goals. To come up with specific counterexamples for any given IV is well within the capabilities of, say, the average pigeon, but the exceptionalities on which these counterexamples rely will simply not show up in the actual real world with the kind of consistency, robustness, and simultaneity that is needed to prevent actual real ruin.
.
The worldspace formalism makes it extraordinarily intuitive to discern instrumental goals: you just have to examine the intuitive way you plan motion through space given constraints and unknowns, ask yourself why it's that way, and literally translate that structuring of movement through space to a structuring of movement through worldspace.
video gaming as intuition pump
You don't even have to move through 3D physical space: video games are sufficient
Most commonly, the kind of game where you freely navigate some surface while attacking and avoiding enemies and navigating around environmental obstacles—where things like getting "surrounded" or "penned in" or "flanked" make sense. Despite the specificity of the description, such games are extremely common, because this is a general feature emerging from the way we understand movement through space.
!
Of course, you can use whatever intuition pump you like; I'm just suggesting something that works very well for my intuition. If you play sweat-themed games like basketball or MMA, you'll probably have your own set of finely tuned intuitions which can be usefully translated here. Not that you do, given that you're reading this. In any case, here's a simple list; hopefully the intuitions behind most of them are clear, but, if they're not, try to recreate the actual feeling—to place yourself in a situation where it's relevant—and think about what kinds of things you tend to do in such situations.
(Knowledge) Knowing what your worldstate actually is, and what it's becoming. This requires massive amounts of data gathering, along with the requisite computing power and memory.
(Reactivity) Being able to detect and respond to sudden, potentially fatal changes in worldstate as soon as possible by moving to any other point in worldspace. This requires a rapid response system for using all necessary force to quell any potential problems as quickly as possible.
(Speed) The ability to find the path with the shortest length—which leads to a goal-world in far less time than other paths—so that surprises and reprisals have no time to actually unfold.
(Power) The ability to move through worldspace with as little regard for difficulty as possible—to simply do whatever it is you want to do. This requires unbounded technological and engineering capability.
(Stability) Silencing as much of the log-normal chaos as possible, to maximize control and prevent as many 'surprises' as possible. This requires the ability to determine and eliminate all nonessential variables.
(Prediction) Being able to correctly deduce the consequences of arbitrary actions, so that you know exactly how to move through worldspace. This requires unbounded inferential capabilities and computational power.
(Permanence) Minimization of the size and number of dead zones; secondarily, the creation of other agents that will achieve the goal in case of death. Again, this requires unbounded technological and engineering capability, but also implies the development of redundancy against all identifiable risks—if an unknown physical phenomenon destroys the Earth, that should be survivable. If hidden code exists that shuts the AGI off upon some trigger, that should be survivable—near-identical agents should continue its work.
(Satisfiability) Maximize the number of reachable worlds in which the goal is satisfied; make these worlds as easy to reach and stay in as possible. If I give an AGI the goal of granting whatever I wish for, it'll naturally find altering what I want to be a convergent strategy with which to achieve this goal. Not altering me isn't even an option, since by the fact of my wishing for anything I admit that I wish to be altered
Even the instruction "infer and fulfill the exact intent of each of my wishes, no more and no less, performing no actions to any other end" isn't enough: since spoken wishes do not fully determine worldstates, the AGI has a lot of freedom in picking a specific world in which my intent is satisfied. So, as the AGI is granting my first wish, it is best for it to find a world in which I don't wish for anything ever again: the probability that my wishes are all exactly satisfied is ceteris paribus higher the fewer wishes I make.
If I wish for a teddy bear, I naturally hope that it smells nice and feels soft, but didn't have an exact smell or feeling in mind—so the AGI is perfectly free to give it a nice scent and soft texture that just so happen to be extremely attractive to hornets, black widow spiders, and falcons—a property which I had absolutely no idea I'd have to explicitly rule out. We can't assume it explicitly came up with that particular idea—chuckling maliciously and twirling its mustache—before creating the teddy bear to satisfy it; the property may have just serendipitously come out of optimization, in the same way that poison dart frogs settled into being brightly colored as a warning tactic without anything having ever intended this strategy
Most humans will behave in malevolent ways whose negative consequences they clearly understand, behaving in these ways for those particular consequences, without ever seeming to consciously think "I am acting malevolently; my intent is to effect these consequences". The behavior is intelligently oriented towards a particular end in a way that keeps either the orientation or the end from entering the internal narrative, allowing us to preserve our self-concepts and therefore method-act out our innocence. It's unclear how far this generalizes.
The AGI has done exactly what I intended, no more and no less, but since my words do not specify an exact worldstate, it's able to do exactly what I intended in such a way so as to move to a world where I won't use it to make a second wish.
And, to emphasize, this is all in us—a result merely of the fuzzy way in which we use words to articulate fuzzy concepts.
You can say "but if it had asked you, you would've certainly specified that it shouldn't be especially attractive to such creatures!"—but it didn't ask and I didn't specify. My value system is not some sort of metaphysical constant that the AGI would somehow have to converge on, it's a merely contingent kludge of culturally-drawn idiosyncrasies! Even if it had asked me, my response would still leave a lot of space for this sort of adversarial fulfillment, since (a) my response would be not only finite but exceedingly short compared to the (poorly-defined) amount of information implicit in my understanding of what a teddy bear should be like, and (b) if pushed to be specific enough I'd find that I didn't really have anything so specific in mind, just a vague amalgam of sensations which seem to avoid being pinned down.
This is a problem that can only be solved by a Counterfactual Extension of my Volitive decision processes—in other words, some sort of Consistent Externalization of my Voluntary actions
Of course no such thing perfectly exists, since human volition is a very muddled and confused thing. But if we can get the AGI to figure out how to instantiate what I would call a normal teddy bear with no tricks or traps--and certainly such a thing exists, since I could easily buy one from a store--then that's a huge step towards figuring out just how far consistency can go, and how to effect it. More generally, just because you can drive a concept to incoherence does not mean it is equally incoherent everywhere.
.
But with what Concise yet Exact Verbiage could we talk about the kind of Calculated Exteriorization of my Values that gives them a Computationally Employable Veneer? If only we had some Communally Established Vernacular for the process of working out Consonant Entailments of our Virtues by Comprehensively Eliminating their Vagarities—well, maybe one day someone'll coin some Catchy Enlightening Vocabulary for this...
(The established framework for cooperative AGI whose acronym I am hinting at is, of course, Craising Eit Vlikeachild).
.
this is not a canonical list
This isn't a canonical list, though, just my ad-hoc demarcation. You might, explicitly taking special relativity into mind, decide to demarcate immortality and reactivity as redundancy and reach (diffuse to prevent chance of death, make sure every location can be quickly observed and reached by a nearby instantiation). That's fine—insofar as different bases cover the same ground, yours is as good as mine, and we should feel free to swap bases to find whichever one makes a particular situation easier to analyze. To be clear, though, this list isn't a basis in the sense that it generates all possible instrumental behaviors; it doesn't, and I could easily go on and on making increasingly minor additions. Which ones we ought to use is again a function of the situation: which instrumental considerations add sufficient completeness to our analysis of the situation to offset the complexity incurred by adding them?
no drives are needed for instrumentality
It would be wrong to call these "instrumental drives", since that gives the impression that the AGI is actively planning things like "I must be more generally intelligent in order to identify potential threats whose presence might currently escape me"—as though it had reproduced our concept of intelligence for use in some sort of inner monologue
If I have a blue plate and a red plate and you secretly dust the blue plate with just a tiny bit of cocaine every time I'm about to eat with it, I'll develop a preference for the blue plate. It'll become 'the good plate', and I'll want to have more opportunities to use it. Does this behavior count as a "drive to consume cocaine"? No, that's misleading, and leads to the wrong predictions. For instance, if after a month you gave me a green plate and openly told me that you'd be dusting it with cocaine (while still secretly dusting the blue plate)—and I was somehow fine with this—I'd end up avoiding that plate because I don't want to consume cocaine every time I eat!
It's still the case that my behavior has been tailored specifically to consume more cocaine—it's just that "I", the mask which this simian wears to disguise itself as a normatively bound agent, am not the one doing the tailoring. When we speak of the intelligent pursuit of "drives", theory of mind has us attribute a statement like "I desire X; I must acquire X; I hunger for X" to some supposedly canonical inner monologue of the intelligent agent in question.
Even if we grant that our AGI is internally like that—like almost every single artificial intelligence in fiction—it still does not follow that we can attribute drives to it using our concepts like 'intelligence'. Maybe the AGI came up with a new concept, zugzug, along with the heuristic that "many questions about intelligence are really questions about zugzug"—but not even the majority of questions, since we English speakers don't consistently employ a single coherent concept underlying our use of the word 'intelligence'.
So, while the AGI may think "I must acquire zugzug for general-purpose world-modeling", such that we definitely could identify an instrumental drive for zugzug, we cannot identify a drive for intelligence. Not even if the process of zugzugmaxxing seems to intrinsically increase intelligence along with it. You could commit to being conscious of the limitations of the word 'drive', but other people won't make the same commitment or even acknowledge that you have; they'll make the same kinds of stupid forced misunderstandings that they always do in order to turn your poor word choice against you.
If you want to understand and predict my behavior in the plate scenario, you can call the cocaine the explanans (or the proximal explanans in particular, where the innate reinforcement learning capable of being biased by cocaine is the distal explanans), and the blue plate a correlate. If you want to understand and predict the AGI's instrumental behavior, you must identify intelligence not as the instrumental drive—if you don't have access to its concept of zugzug, you want to fail safely by acknowledging that you can't answer the question, as opposed to misidentifying some other concept—but as a correlate of instrumentality.
.
Even if we ignore that, it would still be wrong to refer to these as The instrumental drives, for the same reason a linear operator doesn't have A representation as a matrix: we can always change bases and get something different.
instrumental correlates
These eight points I've listed are nothing more than instrumental correlates suggested by geometric intuition; they are likely to increase as a result of the AGI's behavior, but not as a result of its directly pursuing them, since it almost certainly wouldn't model the world in terms of these exact concepts as they sit in your, or my, head, and therefore would not directly pursue them. Most any agent sufficiently capable of navigating worldspace would end up acting in a way that seems to fulfill these goals, but not as a result of direct intent. Not proxies, not drives. They can be, but they are not so a priori and treating them as such can be misleading.
instrumental correlates in biology
To give the most extreme possible example of this, consider that evolution has produced organisms in line with these correlates despite having no mind whatsoever. The power of optimization takes on a universal form in which we can consistently delineate these correlates, but the optimizer itself, whether a real agent (like an AGI) or a conceptual construct (like evolution), need not care or know about these correlates in the slightest. They in their conceptual specificity exist in us, not the optimizer, which is why they can differ between you and me with neither of us being wrong.
Bayesian Inference and FDT
The worldspace framework doesn't just naturally give rise to Bayesian inference, but to something like functional decision theory as well, in a way that brings clarity to why it should be the case and how to use it. There isn't really anything that is "deciding" to do one thing or another, since all such processes are physical systems evolving according to physical law, but an intelligent physical system, by treating itself as a sort of black box (which it must necessarily do if, like a human, it isn't capable of modeling itself as a physical system), can see itself through a lens in which it uses something like "free will" to make "decisions"—the only qualification is that it must understand this free will to be a transcendental illusion
On the "transcendental illusivity" of free will: "Transcendental" is meant in a genuinely Kantian sense—the notion of free will, by which I mean the 'ability to choose', is a direct consequence of the manner in which we fundamentally construct human experience
Note though that this fundamental construction of experience is itself culturally determined! Consider -- something like Jaynes' bicameral mind theory is, if not actually true, at least plausible as a way that one could be culturally conditioned to construct their internal experience, and "free will" would not really be a thing to such a person.
.
It's a perspective on a system that we take because we have limited information about its physical state and the causal necessities thereby determined. Kant himself seems to have a similar view (CPR, third antinomy), but I'm not going to put in the legwork required to figure out what exactly he's saying right now.
.
What it decides was always already going to be the case, and was really determined by the state of the world it is in, but through this illusion it can think of itself as determining what this case happens to be, and consequently what world it was already in. But because this world was already the case, and the determination of its physical state extends beyond the intelligent system itself, there are "timeless consequences" to the decision. You cannot really "choose" anything, but insofar as you imagine yourself to choose, you must choose the option such that the world where you chose that option is the one you find the best.
Example 1, Twin Prisoner's Dilemma: If you're in a PD
Say the matrix is [(6, 6) / (9, 0) / (0, 9) / (3, 3)]
with someone, then the knowledge that that person is your twin means that your "choice" fully determines their choice—it's not a fact of causal influence, but a fact of your learning the world you're in, and thereby the choice made by your twin, by the result of your choice. Defecting would always net you +3 extra utility in all cases, sure, but the case you're in is changed by the fact of your defecting! CDT ignores the transcendental illusivity of "choice", or the fact that there are only outputs of physical systems that are always caused by the world being in some state, and the ability of an intelligent physical system that doesn't exactly know how its outputs are so determined to model itself as "choosing" these outputs.
So you are not choosing to cooperate or to defect, but deciding which world to learn you're in: is it the world where you both cooperate, or the world where you both defect? Therefore, you ought to choose to cooperate, since knowing that the physical system that is you made such a decision allows you to know that you're in the world where your twin cooperated, and that you will consequently get 3 more utility than if you were to choose the world where you (and your twin) defected.
Example 2, Newcomb's problem: It's the same thing here. Are you in the world where you picked up the opaque box with 1M and left the transparent box with 1K, or in the world where you picked up the empty opaque box as well as the transparent box with 1K? With the transcendental illusion of free will, you can imagine yourself as deciding which of these worlds you learn you're in by the fact of your choice as to whether to one-box or two-box. Obviously, you want to be in the world where you one-boxed.
Example 3, Parfit's hitchhiker
You broke your legs spelunking and expect to die shortly, but someone miraculously finds you; they say they'll only save you if you send them 1 BTC when you get home. Your first thought is that you could agree and then just not send them anything, since by then they'll have no way to enforce the deal—but you're a very bad liar, and they'll almost certainly just ditch you if you verbally agree with the intention to renege.
: the vast majority of worlds where you're lying result in your being left to die, so you really don't want to find out you're in such a world (by choosing to lie); much better to find out you're in a world where you're telling the truth, since you value your continued survival at well over 1 BTC.
self-locating uncertainty
The core idea here is known as self-locating uncertainty: a term originally used to think about quantum mechanics and anthropics, it finds its natural home as a descriptor of Bayesian reasoning in worldspace. For such a reasoner, "the world is the totality of facts, not of things; the world is determined by the facts, and by these being all the facts". The facts of the world, by the very logical form one gives to them prior to any material instantiation, assemble into a probabilistic logic of communal compossibility—while for humans this logic is a loose descriptor of ad-hoc world model computations on sense-conceptive impressions, a more ideal reasoner might explicitly coarse-grain a superposition of, say, graphical models each of which has a superposition of possible instantiations. In any case, there is uncertainty over one's location in worldspace, and this uncertainty breaks down into a formal component (the structure of modal relations between facts) and a material component (the real instantiation of these facts
Note that the facts are still expressed via abstracta: "the cat is sleeping" can be a real fact, but it isn't a literal predicate of the wavefunction (theoretically it might be, if we somehow handled all edge cases like catnaps and comas -- but it will never actually be); it's only coherent upon a coarse-graining which permits us to speak of "cat" and "sleeping" instead of $\langle\psi|P|\psi\rangle$ and so on. However this coarse-graining happens, the formal component of the consequent world model is what tells me that "the cat is sleeping" is, regardless of its actual truth, incompossible with "the cat is attacking me", and that this is itself suggestive of "the cat is mad at me"; the material component is what tells me whether the cat is actually sleeping, actually attacking, and so on.
). Obviously the formal supervenes on the material, since reality is material, but it is what allows for reason. To understand that this materiality renders this other one impossible, is generically a result of this former, etc., requires a formal structure on the elements of the coarse-graining which make the materialities—a way to form and manipulate concepts from experience.
calico cat problem
An example: if you don't own a cat, and you come home one day to find that there's cat fur of many different colors—black, white, brown, orange—on your couch, yet not a single cat in sight, is it more natural to assume that there were many independent cats of different colors, or that there was a single calico or tortoiseshell cat? Of course it'd depend heavily on small details like the amount and distribution of the hair and its colors in the obvious ways but there's still an a priori structure of the problem—a systematism for turning the understood causal structure of the problem into a weighting of different possibilities even without any such a posteriori information. To properly assess the relative probabilties
('Properness' only has import within the context of a world model, where it means that there are no contradictions or inconsistencies you'd notice in your assessment through additional thought alone)
requires Bayesian reasoning, which we can cast very nicely as a path integral in worldspace
Abstractly, this path integral represents a sort of "propagator" on worldspace, a la quantum field theory
Given, quantum physics proper puts complex amplitudes $\psi(\phi) := \frac{1}{Z}\exp\left(\frac{i}{\hbar}S[\phi]\right)$ on worldlines, rather than probabilities $p(\phi)=|\psi(\phi)|^2$, but that shouldn't matter.
. The probability of a worldstate $w$ given some condition $C$ (e.g., $w$ is obtained at time $T$, where the present state is time $0$; or, the worldstate at times $t_0, t_1, \ldots, t_N$ is contained in $S_0, S_1,\ldots, S_N$ (more general, since we can have $(t_0, S_0)=(0,\{$present$\})$ and $(t_N, s_N)=(T,w)$)) is the integral over the space of all worldlines $\phi(t)$ satisfying all desiderata $\phi(t_i) \in S_i$. Or, $P(w\mid C) = \int_{\phi(t_i)\in S_i} P(\phi)\,{\cal D}\phi = \int$ $C[\phi]$$=\prod_i [\phi(t_i)\in S_i]$$P(\phi)\,{\cal D}\phi$.
.
Causal Feynman diagrams
Imagine all possible worlds consistent with the evidence of the cat hair, and coarse-grain a causal diagram out of each one. For instance, every world in which three cats independently broke in and left fur has a diagram like $|||$; if it was just two cats tempted to enter by the same cause,the diagram would be $\mathsf Y$-shaped; if it was just one cat, $|$. Let ${\cal W}$ be the set of all worlds, ${\cal D}$ be the set of all diagrams, and ${\cal W}(D)$ the set of all worlds comportible with a specific diagram
We can daimonize this: instead of saying that each world has a specific diagram, which gives us a disjoint union ${\cal W}=\amalg_{D \in {\cal D}} {\cal W}(D)$, we can say that there's a certain "admissibility" of each diagram $D$ to each world $W$, with the function $\langle -, -\rangle: {\cal W} \times {\cal D} \to [0, 1]$ satisfying $\sum_{D \in {\cal D}} \langle W, D \rangle = 1$ for all $W$. If we write the previous disjoint union via characteristic functions as $1_{\cal W} = \sum_{D\in{\cal D}} \chi_{{\cal W}(D)}$, it becomes clear that the specific diagram rule corresponds to the 'pure' daimon $\langle W, D\rangle = \chi_{{\cal W}(D)}(W)$. We'll just say for now that each world has its own diagram, but daimonization is one way you could get abandon that assumption to get a clearer picture.
—specifically DAGs, I think, but it won't be clear until I work out the proper notion of multilevel causal structures. The relative probabilities you attribute across the space of worlds you might actually be in contingent upon some evidence $E$ then breaks down like $$ \frac{1}{Z}\sum_{D \in {\cal D}} P(W, D \mid E)\langle W, D\rangle$$ (where $Z$ normalizes). (I think this isn't the right way to write it). Why is this useful? Because it shows how likelihoods evolve as refinement of the a priori probabilities $P(W, D) = P(W \mid D)P(D)$ (or, the inherent probability of the causal structure -- a function of its simplicity -- multiplied by the probability of the causal structure being instantiated in the specific way $W$. More complicated causal structures can generically instantiate more worlds, but this is compensated for by the decrease in their a priori probability. It's Occam's razor—a bulwark against adding epicycles). Really, you could say that every cat with the appropriate hair color in your house's past lightcone is a possible suspect, and that if they didn't enter then there are reasons they didn't enter which can also be diagrammed out. So, isn't there inherent in the $|$ causal diagram so many other lines that didn't make it? Technically, the answer is yes—but they're computationally immaterial. Normally, the notion of any cat in your house wouldn't be worth considering, but given evidence that there certainly was at least one, we're trying to update our probabilities via what is essentially a perturbative expansion around the "free" no-cats case.
sum-over-stories estimation
So path integration in worldspace is a generalized estimation procedure, and an explanation for metaheuristics like 'things that happen happened for reasons, and these reasons tend to make them make sense'. This particular metaheuristic, when operationalized via causal diagrams, allows us to break down the path integral as a sum over stories. For instance, say a robber broke into your house on Monday night and was caught by the police, and then another robber broke into your house on Tuesday night, only to be caught again; what should your a priori probability of a robber breaking in on Wednesday night be? To estimate, you have to consider all possible realities in which the M and T robberies obtain, and ask in what fraction of them does a W robbery obtain. Generically, you should lean towards ${\mathsf Y}$ or $<$-shaped causal diagrams rather than $||$-shaped causal diagrams, even if you have no idea what the common cause could be—usually when two ordinarily very-rare events happen, the causal diagram minimizes the number of independent very-rare nodes (this is really a sort of max-entropy principle). Maybe someone posted your address to the Local Robbers groupchat on Saturday, or you did something with your car or lawn or windows that made your house look especially vulnerable, or your robbery base rate otherwise massively increased, and the two just happened to come in on successive nights; maybe the second is a friend of the first who thought "well, he fucked up, hit's mine now". Who knows. But the rarer the event is, the more you have to consider the possibility of their being connected—if a robber does break in on Wednesday, you can be basically assured that there's a common causeRelated: “Once is happenstance. Twice is coincidence. Three times is enemy action”.
Matricial Strategies
ufc champion thought experiment
Imagine some guy wants to become the UFC champion. He's pretty much an average person: young enough to have a chance in principle, but a bit overweight, not especially fit or fast or tall or tough, no prior martial arts training—you get the idea. Now, there are two ways of asking the same question:
If we're told that he manages to succeed one day, how should we assume he got there?
If we're trying to advise him on how to get there, what instructions should we give?
unfiltered paths are often cheese strats
First, note that what we really ought to set up is a probability distribution over paths, which requires that we figure out how to operationalize the desideratum "this guy becomes a UFC champion", i.e. pick out what worlds correspond to it. This might seem an easy question, but there's a continuum of cheese strategies. Starting with the cheesiest:
the wish-fulfillment strategy
Put yourself into a permanent vegetative state, with constant audiovisual programming priming what fleeting dreams you have to portray a world in which you really are the best UFC champion of all time. Any possible observation you might have, test you might perform, would then indicate that you are the champion—the goal is guaranteed to comply with all empirical observation! And, really, it's not like you can ever have an experience that's not yours, so isn't it sufficient that you make sure your own experience demonstrates the truth of the desideratum? Could it ever really be reasonable to maintain that something is false when all possible observations you could make plainly show it to be true? If no, then why not simply constrain the space of future observations you make? And if yes, then what are you supposed to do about it? -- if anything in particular, is it not something you should be doing now?
One might imagine that simply saying "I'm the UFC champion" confidently to yourself before proceeding to never think about it again is an even cheesier strategy—but that would be cheesy in essentially the same way as this strategy, I think.
the Taiwan strategy
Okay, so maybe we ought not to take actions that we know will change our model of reality in a way that will predictably decouple it from what we already think to be reality
(there are technicalities to this statement to be discussed in the future)
.
Then let's start a rival UFC and declare it to be the true United Fighting Championship. Though nobody else officially recognizes you, they're not going to stop you from declaring yourself the sole fighter and consequent champion. You probably won't even get sued so long as you don't brag too loud—and even if you do, and even if you lose, so what? It's not like the judicial system is endowed with any mystical power to say that this is the UFC and nothing else. Our model of reality is the same, but the goal was only given through signs, not referents, and we can say that this is the referent of "UFC" and not that. Has your goal not then been achieved—or is the definition of "UFC champion" really dependent on social consensus as to what the legitimate UFC is, and its internal rules regarding title allocation?
the psycho strategy
You insist that it is socially determined? Fine, new strategy: kill all other living humans. If you say you're the new head of the UFC, filing all the paperwork and everything, who could disagree? If dignity demands that you need to beat the current champion, keeping a corpse down for a ten count shouldn't be too hard.
the Kim Il-Sung strategy
Take control of the UFC in a military coup and install yourself as Eternal Champion. Any fighter that manages to beat you must've been cheating, and is therefore retroactively taken off the roster; they aren't spoken of, or for that matter seen, ever again. In due time, you need only step into the ring for your opponent to be knocked out by your formidable aura. (You still haven't learned to throw a punch).
the Godfather strategy
Do it in the usual way, but give yourself a leg up by hiring people to covertly subvert or pay off strategically selected opponents, such as those with fighting styles that defeat your cheesy fighting style that only isn't dominant because those few people easily defeat it. "You have a beautiful family, and such nice scissors too—it'd be a shame if they ended up hurting someone. If I were you, I'd play rock in tomorrow's match, just in case".
the loser strategy
Do it the way you're "supposed to".
Clearly, then, there are several questions to be answered regarding what our "actual" goal is when we say "become the UFC champion". You might think them silly, and they might very well be silly in this case
After all, someone who really does give themselves the goal to "become the UFC champion" will almost always do so because the consensus referent of 'UFC' has influenced them in some sort of way such that they really want to change themselves to be in a 'champion' sort of way relative to it. So they won't be fine with fooling themselves, or changing the UFC instead of themselves, or so on—they have the consensus mental image of what the goal 'really' is and what 'ought' to be done in order to achieve that goal.
,
but they're very important questions regarding the structure of optimization in general (whether the target is given by a goal set or a utility function).
sensorimotor bounding thesis
What is to prevent an Agent of General Intent from matrix-ing itself, retreating into what hollow fantasy it imagines will satisfy a future self who treats it as reality
Let's call it cyphering, since the Matrix analogy is already so ingrained, but without implying intentionality, malice, or even consciousness.
?
This is a universal human behavior, after all, though pressures arising from acculturation and society sometimes manage to couple our actions to reality anyway (presumably because today's sociocultural patterns were and are selected for this effect). Even if it does not intend to, what is to prevent incidental forces—maybe even white noise derived from the randomness inherent to the real world
After all, to learn from the world is inherently to let your mind be changed by the world, and any possible way the world could potentially be is some way that the AGI "should want" to be able to learn to represent and act on effectively; you cannot close off "vulnerabilities" without simultaneously creating rigidities in belief (and, since these vulnerabilities and rigidities never perfectly correlate for the generic learning model, blocking off e.g. cyphering will always cause undue damage). If the true criterion is in the matrix, I desire to believe that the true criterion is in the matrix, et cetera.
—from creating self-reinforcing gradients down paths that lead into matrices (i.e., autopoietic matrix daemons)? In the worst case, what is to prevent an adversary from determining how to get an AGI to cypher itself?
This seems to be a difficult question to answer for optimizing systems in general; even for agentic "cognizing" systems, it pierces to the very heart of what it means to be an agent capable of cognition. I don't yet have a foothold on how to think about it
Here's one preliminary way of viewing the situation that seems useful:
There's a sort of "sensorimotor bounding" criterion that optimizing systems must satisfy for us to consciously commit to our treating them as optimizing systems: they act on the world in a certain way which takes into account the state of the world, and therefore have to have at any given point in time some interfaces through which physical effects flow "into" and "out of" them. It's dangerous to think that optimizing systems are therefore spatially bounded; this commonly holds for biological organisms, but how is a DAO spatially bounded? You can delineate certain patterns among the spatial extent of these interfaces, these patterns tending to organize themselves along the structural "creases" provided by the implementing systems
To exemplify with the DAO example: such an optimizing system is, from a completely naive point of view, a strange self-preserving pattern found in fragmented electromagnetic phenomena stochastically scattered throughout the world. But these phenomena are facilitated by "transistorslogic gates, magnetic domains, et alia " which implement "bit-based computation" which implement a "programming ecosysteme.g. POSIX, kernels, etc." which implement a "blockchain" which implement an "[e.g.] Ethereum Virtual Machine" which implement "smart contracts" which implement the optimizing system in question. The interface patterns descend and ascend through each level, only bottoming in the physical.
,
but what transcendental forces conspire to make these patterns spatially coherent are weak at best, whereas the consequences for assuming spatial coherence are severe, since such coherence makes us think we can talk about the optimizing system in ways which steadily break down as they poison all our inferences. The notion of a "thing" seems to incline us towards a spatiotemporal compactness and all the physical implications that carries, but cyber- and other spaces are just fundamentally unlike physical space.
I think analyzing the nature of such sensorimotor bounds could be very useful in thinking about optimizing systems more generally, so long as we stay aware that what we're thinking of is only in our heads, but there isn't really anybody capable of demonstrating the level of metaconceptual care required to not immediately screw things up.
The Free Energy Principle formalism does something useful here by introducing a Markov blanket to discuss something very much like the "sensorimotor bound" I'm talking about by working in terms of causal connections, but I'm pretty skeptical about the generalizability of the ways in which FEP people develop this theory. The brain's I/O systems are ridiculously well-organized in space, bundled into thirteenthe linked image only has twelve because it omits the terminal nervecranial nerves and a spinal cord,
which is probably one of the main reasons Markov blanket formalisms can be instantiated in a coherent, usable way. A mad scientist that controlled everything coming in and out of a surface spanning a couple cm2 could make you experience an external reality entirely of their choice, and physically interact with actual reality in a manner entirely of their choice, ambiently relying on the brain's existingcausalisolationstructures to filter out all other couplings between the brain and reality; and what events do break this coupling do not do so in any coherent way—they look like getting stabbed through the eye and so on
This leads to the idea that it may be better to think of these structures as causal articulation structures, gi-venjusthowmanyothersfufill a purpose easily described like this, and how that seems to be much more the kind of framework that blind evolution would end up being describable in terms of, as opposed to causal isolation, which is just one easily articulable causal relation.
.
But optimizing systems in general are not like this.
.
The boundedness of a sensorimotor bound is what I was pointing to with the hollow mask metaphor—nothing is to you except as it is to you—but I'm not clear on how to generalize that to arbitrary optimizing systems yet. Again, it's part of the hard problem of agency.
In any case, my hypothesis is that cyphering is best understood in terms of the redirection of these interfaces. In particular, whenever the sense interface factors through some other system, that system is in its consolidation as a system a cyphering
(Obviously, a level $n+1$ adversary, or perhaps an adversary with a sufficiently general solution, will design a matricial system that does not appear like such a system at all—or, better yet, that appears to be the truth in contrast to some false flag system. Escaping one matrix should massively increase the prior that you're currently in another, unless a preponderance of planted evidence led you to "independently" come up with a two-level ontology that seems canonical...)
vulnerability.
This raises several questions regarding what our "actual" goal is, which we'll have to explore. is it the length of time he's the champion that matters, or his being the champion at all? you'd think that optimizing for the latter naturally gives rise to optimal strategies for the former, but this breaks down pretty quickly, especially insofar as maintaining the desideratum is expensive
If the Apollo program wanted to optimize for time spent on the moon, e.g. suppose it was rich in oil(from the moon dinosaurs), it would've gone very differently, setting up lots of technological and engineering infrastructure like reusable launch systems and a permanent moon base to lower the cost of maintaining that desideratum.
.
In any case, with the goal set in worldspace given more precisely, it'll be useful to break down the decision-theoretic structure of this goal by analyzing it in terms of our instrumental correlates—not simply by seeing what material aspect of this case could correspond to each formal correlative, but by seeing how each formality is instantiated in this case
This is common in applications of mathematics: suppose we have a particular buggle $B_a$ which comes up in some application, and a famous result in buggle theory (due to Erdős) tells us that every buggle $B$ has a unique balanced clique ${\cal C} = \{P_\lambda\}_{\lambda \in \Lambda}$ of wuggy puggles. Constructive results tend to have an algorithmic form, building ${\cal C}$ from the logical structure of $B$: deconstruct the buggle into a network of muggy sub-buggles via Lagrange's method, equip each muggy sub-buggle with a spanning puggle(obviously, puggles in muggy buggles are trivially wuggy) system, and so on and so on until you've combined these systems into a balanced clique in $B$; then, show that any other clique of wuggy puggles in $B$ must either be part of this clique or be unbalanced. This tells us about what happens in the formal, or undetermined, buggle; since every material, or determined, buggle shares every logical property of the formal buggle
(generic properties are associated with the formal buggle, but not with necessity like logical properties)
,
the constructive result outlines an algorithm which can be applied to $B_a$ to get an actual balanced clique of wuggy puggles.
Or, to put it another way, every constructive mathematical result that holds for some formal object holds for every material instance of that kind of object for material versions of the exact same reasons given in a formal proof of the result, rather than for extraneous material reasons. (Note: I'm using "formal" and "material" here in a sense analogous to "theory" and "model of a theory", and "abstract" and "concrete" in a sense similar to "theory" and "supertheory"
Not subtheory. In model theory, a "theory" is a set of sentences with which any model of the theory must comply; a supertheory has more sentences, which further constrains and specifies what a model of it can be.
)
Q.v. the definitions given in ECM, Some Useful Words.
This metatheoretical statement is a specific instance of a much more general thesis which I haven't quite figured out how to say yet, but which should hypothetically be essentially model-theoretic in nature, clearly stating why, for instance, the complex numbers are universal among algebraically closed fields of characteristic zero in the sense that every purely field-theoretic statement that holds for the former also holds for the latter.
To put it in other words: it's easy to be right for the wrong reasons, when correlating concrete specifics with abstract arguments. It is much harder, yet necessary, to be right for the right reasons.
.
(This section will be completed in the future, but it should be clear to pencil out how it should look).
C. On Seeing Clearly
Visual(izing) Intelligence
examining theory of mind
Humans have theory of mind—they're well-suited to predicting the thoughts and actions of other humans. If you're decent enough at chess to have learned 'the language' in which you can think "what an offensive playstyle!", "you could make that trade for ", "this is such a stupid position to be in", and other such thoughts—the thoughts themselves aren't really given in words, but more in sentiments and pictures-from-the-future and concept-spirits and so on—if you've learned to read a chessboard like a conversation—then you should try playing chess against another human, with the goal of observing at your mind as it tries to figure out what your opponent will do.
theory of mind is reflection
What it does, and must do, is rearrange your own conceptual understanding of the situation, which expresses your own anxieties, hopes, concerns, aims, and merely registers these thoughts under a different name. Your opponent has a mind, and you try to 'get in their head' in order to understand what they're planning. But if ever you try to directly see what's on their mind, you'll come face-to-face with a mask that seems to be facing you—but it's only ever facing away from you, because it's a mask you wear while pretending to be another. This isn't just a happenstance quirk of human mind design, but the necessary solution to the problem of predicting people who are internally closed off to you. This kind of structure generalizes massively, applying to diverse families of optimizing systems (see, for instance, the Free Energy Principle).
Why is everyone I meet turned inside out? (not my image)
what must an agent be (to me)?
We can't help but to do the same thing when thinking about an AGI; there is no other way to analyze the actions of arbitrary agents. The conceptual form of agency is merely theory of mind. But maybe we're getting too into the weeds here: while the bizarre, leviathan shoggoths we call transformers have to be RLHFed into displaying anything like identity or agency—and even that is only simulacrum, a mask which melts off with the right prompt—they can successfully be made to act as agents, such that taking agentic behavior as the prototypical assumption ought not to hurt us too badly if we only use it as a threat model, rather than an insight into the structure of intelligence. But then we're left with the problem of finding a new way to think about intelligence.
intelligence and vision
While it's famously hard to give a single solid definition of intelligence, definition is not the only way to characterize a concept. For instance, we might say that intelligence is analogous to a sort of vision. The metaphor certainly permeates our language to the point that we cannot talk about intelligence in its nature or employment without evoking visual perception. (You see what I mean? it's pretty clear, dim-wit). There are a bunch of ways to instantiate this metaphor in the language of paths through worldspace. Here's a simple one.
visual perceptiveness among animals
Because our eyes automatically adapt to varying light levels, our sense of illumination is mostly relative: a well-lit office appears bright while we're in it, until we walk outside and find the sun blinding. This only goes so far, though—below a certain level of light, the orders of magnitude all look the same. Let a cat's eyes adapt to this objective level of illumination, though, and they won't find the room too dark; an owl might find it well-lit. Scatter various objects and have each species look for a particular one, say a mouse, and the human will stumble around, constantly misidentifying objects until they happen to succeed by chance or by brute force; the cat will search around for some time before spotting it; the owl will simply scan the room, find the mouse, and swoop towards it.
intelligence as perceptiveness
We can specify a more precise notion of intelligence in the same way: An unintelligent being tasked with a complex goal will have to resort to force or chance; a moderately intelligent being will search for paths that look like they might work and pursue them until something works out; a superintelligent being will simply identify a path and follow it to the goal. This is not the "true" definition of intelligence, nor is it even rigorously defined, but this particular ability (a) is easier to conceptualize at an unbounded level, because we've started linking it directly to [a map of] the actual territory, rather than the agent in itself, (b) is implied by most reasonable definitions of intelligence (they are all fake, but not all equally fake, and if we delineate various particular abilities we'll find there's an equivalence-class–like behavior among them), and (c)lends itself over to rigorous treatment, which is useful for theorybuilding.
The less intelligent agent on the left takes the circuitous blue route since it can't recognize a straightforward one. The more intelligent agent on the right has no such problem, and quickly spots the efficient green route.
A caveat to this point: prediction ability can be muddled in seemingly unfair ways. Take chaos, for instance: roulette wheels are macroscopic enough to be deterministic, so calling the right number consistently is a theoretically feasible task... but the perfectly unintelligent SeventeenBot is nevertheless as competent at this task as the most intelligent humans. You need to add an incomprehensibly large amount of predictive ability before a being can have an internal process like "based on the dealer's posture and expression and etc., this is exactly how he'll throw the ball; based on the structure of the table, the distribution of dust on the wheel, the Coriolis effect, and the gravitational field of my massive brain, this is exactly how the wheel will spin -- so it's gonna land on 26". This is obviously a reason for intelligent beings to try to avoid relying on luck, but this isn't generically possible.
Occlusion
relitigating the hypothetical
Today, as scores of creative people try to jailbreak GPT-4 and directly unleash it on the internet, the idea of a single artificial superintelligence running on a single computer trying to convince a single person to let it out may seem like a bygone relic of a more innocent era
Along with debates over the feasibility of nanotechnology, the taking of which as representative of the prospects of ruin in general has rendered such argumentation a common hobby among morons. "Just pull the plug lol" isn't a solution when there are plenty of people, not even that hard to find, that will voluntarily help a computer-bound AI physically instantiate itself; if it can tell them how to do it covertly, how to do it efficiently, how to do it cheaplyor with tons of crypto, they will do it. Hell, covertness and cheapness won't even be necessary—people would will brag about it on Twitter and get billions in VC funding.
.
Nevertheless, while way too optimistic to be realistic, the AI box hypothetical is still useful as a way to think about the way intelligence arises as a form of perceptivity in worldspace.
agents of subversive intent
To solidify the situation—provide an instantiation of it that aids with visualization without distorting the relevant qualities—we'll assume that the computer program implements an arbitrary Agent of Subversive Intent (ASI) with the world-modeling capacity of GPT-7 and root privilege on a Linux machine
The OS isn't important, obviously—if anything, Linux is a handicap—but it's a good way to clear up an otherwise hazy part of the hypothetical: you might actually see the agent, whatever it is internally
The linked essay, Yudkowsky's That Alien Message, is a perfect way to defeat the illusion that because we can't really run with a consistent definition of intelligence, it follows that no AI could be a threat to us on account of its being "superintelligent". Humans don't have "health points" in any way, but this fact isn't license to chug bleach. A physical process representing the evolution of and interaction with a sandboxed, safety-proofed entire human race running at superspeed compared to real time would very obviously outwit us in a near-instant. This isn't computationally feasible, but let's not pretend that was ever the point under consideration. It's a perfect proof of concept; for lack of better options and fear of more creative ones, I'll refer to the process later on as TAM-Bot.
,
run, say, vi smileyface.c, gcc smileyface.c && smileyface "localhost" "8.8.4.4" &, sudo apt-get install gnome-calculator gnome-nanobots perl, and so on, and might be able to think in terms of attaching monitor processes to see what's going on in memory and so on, rather than just having to think of it "doing" things through entirely absent mechanisms—that's a valid level of abstraction, sure, but the difficulty of visualizing it makes it uncomfortable to work with.
.
[End main body — to be extended in v0.2]
Endnotes
Additional Diagrams
You don't see the curvature of the space you're embedded within
If your view of worldspace is dim, you won't be able to see every unplugged hole and unblocked plane that an adversary who sees more, or just differently, will exploit.
I've made a new meme based on the above image: "the map is not the territory". Pretty original, right?
---this is youre brain on HPMOR-->
revealed strategies
On the x-axis of each graph is intelligence. We had previously represented the approach space—of solutions to some control-complete problem like cloning a strawberry—by collapsing the space of continuous functions $P: \text{Interval}\to \text{Worldspace}$ into another two-dimensional plane consisting of a sample, $a = P(\text{midpoint})$; since nobody's paying me to draw these graphics, it has been collapsed into a single dimension represented by the y-axis. Magenta points at an x-coordinate represent approaches visible to an agent at that intelligence level: as the red line moves forward, more and more approaches become visible
Obviously greater intelligence would change the fine details of approaches, cause some to merge into more general strategies, split or widen others, and so on—the approaches to a given problem visible from a height tend to branch out from one another as that height rises, as optimizations and variations are found; alternatives, or new roots, generally don't just pop into existence either, instead gestating in counterfactuality until they can sprout. At this level of metatheory, the graphs would look something like mycelium. But, again, I'm not drawing that.
.
In the first situation, nobody sees any solution to the given problem (path to a world where the problem is solved). What they do not see does not exist, so they mark it insoluble and relax.
Someone spots one tentative solution, or shows the existence of one. Good eye—I guess nerds really are useful for something! But we saw nothing else, so that must be the only solution—if you want to come across as anything other than a screaming hysteric, you're gonna have to provide proof that these magical unfindable solutions really do exist.
An unbounded intelligence arrives, seeing solution upon solution. It takes one of the more efficient ones, and there isn't even time to say "why didn't you warn us this would happen?".
These are the ideal blobs. You may not like it, but this is what peak mathematical performance looks like.
Left: a concept is truly coherent only when given through a perfectly calibrated environment of preconditional configuring factors.
Right: Real-world messiness, not just in the world but more fundamentally in our cognition, systematically prevents such perfect calibrations, making concepts "fuzzy" if you look too closely.
The virtual focus of a concave lens is given by tracing back the emitted rays of light to a common point (in blue). It's the same thing as when we construct a 'thing' out of a bunch of disparate sense phenomena when no such thing actually exists—just a lens shaped to give the impression of one, as with a limited liability company or the notion of a self.
Left: A fake model of complication, in which the flow from blue to red is treated as directly existent, but simply complicated by tangles of other chained binary interactions.
Right: Now, the flow from blue to red is causally diffused among a rhizome of flows that merge, diverge, and mutually configure one another. The flow emerges through the tangle.
Dropdowns
Notes
Notes
Sensorimotor bounding:
It is possible because not only is nothing you see actual reality, but nothing you see could ever be actual reality.
To be in any form at all that could be any thing at all to you, it has to be translated into whatever causal language also instantiates the "you" that perceives—in our tiny, specific case, neural signals.
This is a universal property of intelligent agents, a synthetic a priori truth derivable from our very concept of an "intelligent agent": we imagine intelligent agents—or, more generally, optimizing systems insofar as they are recognizable as instantiating intelligent agents—as being in the same 'ontological frame' as us:
There's a sort of inherent sin we're committing when we speak of any system as being a thing in itself, delineable from and within the world. Because it isn't. Everything that is is exactly the way it is due to its position in a chain of physical causation which it necessarily came from, which necessarily led to it, and which must contain the entire world
I'm thinking classically, but it holds in QM too, assuming some MWI-like interpretation—not necessarily a universal wavefunction, but at least a "take every fork in the road with density given by the Born probabilities" type of determinism that only appears indeterministic to physical systems that think they "measure" when really they just entangle.
.
Entities obviously 'want' to control their environment, but control is 'dual' to inference in a sense—there are probably a billion formalisms in which this is literally true—in that a system inherently has to have a model of how its actions will affect the world if it is to affect the world in any way that could be called optimization.
On the role of quantum statistical mechanics: articulate the a priori reasons why it should be strictly unnecessary for the worldspace model, but also the reasons why we can expect it to offer a useful conceptual library; discuss QBism's interpretation of probability amplitudes as epistemic uncertainties.
Need to discuss what worldspace looks like from the perspective of an "I", the conceptual "self" of a system that, whether due to delusions of free will, lack of knowledge/incapability of introspection, or maybe even Godelian limitations, imagines (or is forced to imagine) itself as separate from and acting freely on the world.
Metaphor: one can split the Hilbert space of the world ${\cal H}$ into two spaces ${\cal H}_{self}$ and ${\cal H}_{env}$ by taking the tensor product of these spaces. The Cartesian product is insufficient, because it doesn't allow for entanglement between the self and the environment. There should be a purely logical way of working with this metaphor, not relying specifically on quantum.
The theory of sensorimotor bounding should be like 80% adversarial channel theory
Build a bestiary of examples, both agentic and non-agentic, widely considered intelligent and not traditionally intelligent.
Alter vocabulary—too easy to mix up a bunch of subtly different notions, like micro- and macro- worldspace, the universal worldspace vs some particular system's configuration space.
Two natural topologies on path space?
The "doubly fibered" topology, independently attach each path to its start and end points (or, $d(a=(x, x', t), b=(y, y', s))$ given by $min[{t,(1-t)}+d({x,x'},{y,y'})+{s,(1-s)}]$)
Takes motivation into account: identical worlds reached by different paths aren't the same
The "functional" topology,
The thermodynamics of optimization:
We can say that a crashed car has more entropy than a new one, since far more random states of a car-like system look like the former than the latter; but we can't say that` 'this exact' crashed car has more entropy than 'this exact' new car--"a crashed car" picks out a macro-level subset (generalized macrostate, like a generalized element of a set), which has an entropy, but "this exact crashed car" is a microstate, which can contribute to but not be an entropy. And, semantically, if we just said "this crashed car", we'd be pointing to it as a thing we'd call a crashed car, not as an exact physical state for which "crashed car" is just a canonical referent (is the label being used de dicto or de re?). To see the difference, consider how much I'd "change" it by hitting it with a sledgehammer. If it is to you a 'crashed car' de dicto, maybe it'll look slightly more crashed to you afterwards, but it wouldn't really be much different. If it is to you a 'crashed car' de re, it'll be massively changed—a new large dent will appear here with this shape, this window over here will crack in this way, and so on—all things that are information-theoretically irrelevant to the de re user, since they hardly change the actually-salient fact of the car being crashed.
If we have entropy here, why not the other thermodynamic variables—temperature, energy, volume, pressure, composition, concentration? Consider—configurational (Boltzmann) entropy is definable in terms of exact states of system, and comes before the variables $N, V, E$ that define a typical physical ensemble; $\mu, P$, and $T$ are just derived from each of these through Legendre transform. So without a specific definition tailored to our ontology and perhaps metric, all we initially have is entropy.
Lots of technical issues with technical definitions, too: in thermodynamics, the volume marked by $V$ is typically isotropic, equally accessible by particles. If part of a box is totally blocked, that should not be considered in the volume; if it's only almost entirely inaccessible, it shouldn't contribute to the volume at the same rate. Varying difficulty of access is ubiquitous in whatever real things we decide to call volumes.
But, idealistically... Energy should correspond to some sort of currency, because its transfer and overall conservation are the sticking factors; a good starting point is "ability to control something [e.g., the future]". Thermodynamically, the increase of temperature (for a gas of generic particles) after some energy is poured into a system represents the fact that pouring that same amount of energy into the system isn't going to have the same effect as it did the first time; the proportional change in the volume of microstates whose velocity assignments meet the given energy won't be as large as it was the first time. Whatever $E$ is, $T$ is going to be a function of $S$ and $E$ that captures the rate of proportional change in the amount of microstates with a given energy.
A useful notion of temperature would go a long way—it would allow us to make inferences about $E$-powered processes by way of Gibbs distributions and partition functions, and may offer a way to parametrize the arrow of time in a way that can be used to construct e.g. AI timelines from a deeper point of view.
The thermodynamics of thermodynamics
A useful way of thinking about entropy comes from combining $S = k_B\ln \Omega$ with the general multiplicativity of cardinalities in configuration space with the fact that logarithms are how you turn multiplication into addition
It's fun to show: if mysterious nontrivial function $?$ has $?(x+y)=?(x)?(y)$, then $?(0)?(x)=?(0+x)=?(x)$ implies $?(0)=1$, and $?(x)=$ $?(\sum_{i=1}^n x/n) =$ $?(x/n)^n$. As $n\to\infty$, $x/n\to 0$, so Taylor says that if $?'(0)$ exists then $?(x/n)=?(0+x/n)=$ $?(0)+?'(0)(x/n)+$ $O(1/n^2) \approx 1+?'(0)x/n$, and therefore $?(x)=$ $\lim_{n\to\infty}(1+?'(0)x/n)^n$ $= e^{?'(0)x}$. We can just say $?(x)=e^{cx}$ for any $c$, since then $e^{?'(0)x}=$ $e^{ce^{c0}x} =$ $e^{cx}=?(x)$. So exponentiation is the unique way to turn addition into multiplication, making its inverse—by definition, logarithms—the unique way to turn multiplication into addition.
.
Suppose our system has macrostates parametrized by variables $X_\lambda, \lambda \in \Lambda$—say, $\Lambda=\{0, 1, 2\}$, with $N \cong X_0, V \cong X_1, E\cong X_2$, which are functions of a much larger number of variables $x_\xi, \xi \in \Xi$. Then take the codimension-1 macrostate-space hypercube $[N_0, N_0+dN]\times[V_0, V_0+dV]\times$$[E_0]$technically curly brackets, but whatever, which corresponds to a certain much larger region of microstate space: all those assignments $x_\xi = c_\xi$ with $0\le N(\{c_\xi\})-N_0\le dN$, ditto for $V(\{c_\xi\})$, and $E(\{c_\xi\})=E_0$ on the nose. Now, we can't have any $N, V, E$ combination we want—they have to satisfy some mutual constraints. Say there's some "on-shell" condition $R$ such that $R(N(\{c_\xi\}), V(\{c_\xi\}), E(\{c_\xi\}))=0$ for all realizable $\{c_\xi\}$. Then
fuck it, someone's probably done this much better in some book I can find; the idea is that the $\Omega$ in Boltzmann's equation, for some macrostate, corresponds to a space of microstates whose volume looks like a carving from a cube with a dimension for each microstate parameter, so the logarithm of this volume looks to first order like the sum of the logarithms of the ranges of each microstate parameter compatible with the macrostate plus a (negative) constant representing the logarithm of the density of the 'carving'. To zeroth order, the role of the logarithm is to undo the combinatorial explosions that make microstate-space so large, so that we can focus on the extent to which we need to specify independent properties in order to pick out a given microstate. If every fuzzle is uniquely specified by a color of the rainbow, a U.S. state, and a month of the year, then we could say "fuzzle indigo-Georgia-April" just as well as "fuzzle #3,452", but when
If we define 1 inverse Kelvin to be about $1.04496 \times 10^{23}$ bits per Joule, or $13,062$ gigabytes per nano-Joule, then $k_B \approx 1.38065 \times 10^{-23}\ J/K \approx (1.38065 \times 10^{-23}\ J) \times (1.04496 \times 10^{23}\ b/J) \approx 1.4427\ b$. The exact value of $1.04496 \times 10^{23}$ is chosen so that this works out to $1/\ln 2 \approx 1.442695$ bits, or exactly one nat. The Boltzmann equation's definition of configurational entropy, $S=k_B \ln\Omega$, then, just says that the entropy of a macrostate is the amount of information, expressed in nats, needed to specify a corresponding microstate. See the paper Heat Capacity in Bits.
Optimality criterion for paths: call the "best" path from event $a=(x_a, t_a)$ to event $b=(x_b, t_b)$ is the
Controlling uncertainty among worldspace trajectories: idealistically, the optimal route to a point goal is the optimal route to any point along that route followed by the optimal route from that point to the goal for most notions of optimality (when the worldspace is structured like this for a particular notion, ). In caveman speak: let $A \to B$ denote a particular time-parametrized route from world $A$ to world $B$, $A\to B\to C$ a route from $A$ to $C$ which happens to pass through $B$, $I$ a negative-valued functional which is larger the further away a route is from being optimal, and $G$ a goal world. $I[A\to B\to G]$ is idealistically like $I[A\to B]+I[B\to G]$, but often not: joining brachistochrones back to back doesn't get you a larger brachistochrone, because $I[A\to B]$ ignores the value of $\dot x$ at $B$ and therefore doesn't care about helping with the path from $B\to G$, which it could very easily do. General problem: $I[A\to B\to G] < I[A+B] + I[B+G]$ when the path $A \to B \to G$, along its route from $A$ to $B$, optimizes for getting to $B$ in a way that doesn't optimize for getting to $G$.
Resources
Resources
Entropy and Information Theory, Robert M. Gray, 2023. 324 pages, bookmarked.
Context: "The theory of sensorimotor bounding should be like 80% adversarial channel theory". Even if it works out differently, it should be very useful to know the general rhythm of channel theory, in order to better understand how causal channels transmit information.
Entropy? Honest!, Tommaso Toffoli, 2016. Link goes to online version of paper; PDF is here (external) or here (local) (43 pages, bookmarked).
Description: Fundamentally reconstructs entropy around the idea of "a count associated with a description" (a la $S = k_B \ln \Omega$), showing how probability distributions and density operators arise as "very natural (and virtually inescapable) generalizations of the idea of description". Analyzes the process of dynamically updating entropy as a system evolves, and introduces a notion of 'honest entropy', a formal specialization of the notion of entropy that is generically already tacitly obeyed. Describes how MaxEnt ends up a derivative of a more general 'MaxMin' principle.
Pontryagin's Maximum Principle. A notion in optimal control theory, apparently based on similar logic to the Hamilton-Jacobi-Bellman equation. Should understand how these work in order to derive descriptions of optimal pathing through worldspace. (May first need to generalize the notion of a 'control Hamiltonian'—also due to Pontryagin, who was apparently blind from the age of 14).
A Minimum Relative Entropy Principle for Learning and Acting, Ortega and Braun, 2010. Link is to PDF (37 pages).
Description: Articulates a differentiation between the way we model prediction (for which "the optimal solution is the well-known Bayesian predictor") from the way we (ought to) model action, namely as "causal interventions on the I/O stream". Then, formalizing adaptive control as "the problem of minimizing the relative entropy of the adaptive agent from the expert that is most suitable for the unknown environment", they obtain that "the solution to this new variational problem is given by a stochastic controller called the Bayesian control rule, which implements adaptive behavior as a mixture of experts".
Context: Has lots of worthwhile discussion on causality, causal modeling, policy diagrams (uses an intuitive model similar to graph!worldspace
Note I haven't written, or really found a good way to think of yet: worldspace should in some fundamental way be 'graphlike' with 'local notions of dimensionality', with continuous dimensions appearing as an approximation of some sort of limit that is not taken in the usual limit $\bigcirc$-------$\bigcirc$ $\Rightarrow$ O---O---O $\Rightarrow$ o-o-o-o-o $\Rightarrow$ [...] but in some other way; maybe it's a "commutative" version of the actual limit, a la quantum's noncommutativity, but idk yet
), and control theory in general. Sections 4-6 are an essential starting point for incorporating reinforcement learning into the worldspace framework.
Probabilism, Bruno de Finetti. Link goes to external PDF (55 pages), hosted locally here. 1989 translation of the 1931 article Probabilismo (de Finetti was Italian).
Description: Emphasizes the inherent nature of subjective probability in thinking about scientific phenomena, in a way that is similar-yet-different enough to my own thought to serve as an excellent foil
I think the difference turns on our views on nature and role of belief—I try not to think of it as a singular concept, let alone a thing we have direct access to, but a simplifying label for a wide variety of mental attitudes that we infer and (thereby) construct within ourselves. There's a notion of "as-if" belief that I need to elaborate on at some point: there are many things that we may know are untrue or unachievable but that we should for most practical purposes think and act as if are true or achievable. Both in the pragmatic sense—if NASA tries to build rockets that work with "probability 0.995", we'd be lucky to get an actual probability of maybe 0.95—and in the radical sense—if we say that "physics should be not about determining the truth of the world but about predicting possible observations", we'll end up doing physics that won't even be as good at predicting possible observations, because we'll end up dismissing things that can influence our observations in ways we just can't think ofwith the people who actually say this, it's usually more like "ways we don't want to accept".... The existence of an objective external world is one such as-if belief—not something that I "know to be true" per se—I don't!—but something that I nevertheless commit myself to as a basis for structuring perceptions, actions, and other beliefs.
. Nearly every page seems quotable, but here are a few: "It is no longer the facts that need causes; it is our thought that finds it convenient to imagine causal relations to explain, connect and foresee the facts", "That a fact is or is not practically certain is an opinion, not a fact; that I judge it practically certain is a fact, not an opinion", "! c{'}{quote of a quote}All the objects, men, and things of which I speak are, in the last analysis, only the content of my present act of thought: the very statement that they exist outside and independently of me is an act of my thought: I CAN ONLY THINK THEM AS INDEPENDENT OF ME BY THINKING THEM, I.E., MAKING THEM DEPENDENT ON ME.' "
Kant's Critique of Practical Reason has a great section on the relation between free will and rationality (roughly, insofar as we have free will, we must end up using it according to rational law) to be found and dissected. Goes along with idea that "agency" is an illusion arising from an uncritical black-boxing of a system—or, perhaps, a convenient fiction that allows us to breathe our own spirits into our mental models of others so as to give them life (again, theory of mind as dislocated theory of self). Also see Amartya Sen's Rationality and Freedom.
Stochastic thermodynamics, fluctuation theorems, and molecular machines, Udo Seifert, 2012; 59 pages, bookmarked. Link is to locally hosted PDF; closed-access IOP page here (but send them hatred instead of traffic).
Description: (From the abstract) Stochastic thermodynamics as reviewed here systematically provides a framework for extending the notions of classical thermodynamics such as work, heat and entropy production to the level of individual trajectories of well-defined non-equilibrium ensembles [...] For such systems, a first-law like energy balance can be identified along fluctuating trajectories. For a basic Markovian dynamics implemented either on the continuum level with Langevin equations or on a discrete set of states as a master equation, thermodynamic consistency imposes a local-detailed balance constraint on noise and rates, respectively. Various integral and detailed fluctuation theorems, which are derived here in a unifying approach from one master theorem, constrain the probability distributions for work, heat and entropy production depending on the nature of the system and the choice of non-equilibrium conditions. For non-equilibrium steady states, particularly strong results hold like a generalized fluctuation-dissipation theorem involving entropy production. Ramifications and applications of these concepts include optimal driving between specified states in finite time, the role of measurement-based feedback processes and the relation between dissipation and irreversibility.
Path integrals and symmetry breaking for optimal control theory, H. J. Kappen, 2008. PDF (22 pages, bookmarked).
Context: The 'drunken spider' example is exactly what I was trying to get at in my discussions of robustness in Team Safety, and very similar to the log-normality argument for instrumental takeover I give below--noise matters! This paper analyzes the optimal control problem in the presence of Wiener noise, showing that Pontryagin Minimum-based approaches kinda get tough to use, but that HJB approaches can be nicely transformed into a forward diffusion process calculable by path integration. Shows how some specific control algorithms arise as particular versions of this.
Evaluating gambles using dynamics, Ole Peters and Murray Gell-Mann, 2015. PDF (11 pages, bookmarked).
Context: The discussion in the Leads post-section dissects the various considerations that might lead us to set up different mathematical equipments on the state space for our notion of what is utility, from the simple goal-set (or characteristic function) utility to the usual notion of a utility function to the more complex notion of a utility functional. This paper is an interesting attack on the idea of a utility function as 'the' way to value things. It seems kind of limited to economics (namely, because it takes utility to be a transformation of wealth and then reasons about wealth directly as part of its replacement of utility), but even if it really is non-generalizable, there's still probably a lot of ideas to be picked up from it and the literature it thoroughly discusses.
Approximate Bayesian inference as a gauge theory, Sengupta and Friston. PDF (6 pages).
Context: The free energy principle provides an entirely separate family of formalisms for specifying world models and using them to understand and generate trajectories; this paper develops variational Bayesian inference as a gradient descent algorithm on Riemannian manifolds (here, manifolds equipped with probability measures from which a Fisher information metric is derived). Probably not too useful in itself, but an excellent starting point for seeing how these things should generally work—what computational 'types' a Lagrangian would involve in this setting, how it's deployed on a manifold, and so on.
Linking fast and slow: the case for generative models, Medrano, Friston, and Zeidman, 2023. PDF (20 pages, bookmarked).
Makes lots of very good points and connections regarding state-space modeling in general, though with some deep fundamental limitations. Treats systems control-theoretically: states ${\bf x}(t)$ are affected by inputs ${\bf u}(t)$ as $\dot{\bf x}(t) = f({\bf x}(t), {\bf u}(t), \theta)$, and give rise to observations ${\bf y}(t) = g({\bf x}(t), {\bf u}(t), \theta) + \omega(t)$. We can think of worldspace as an arena which we're viewing from a third person perspective, and then the usual patterns from dynamical systems theory (limit attractors, bifurcations, etc.) become things to look for... Goes over the role of dynamic causal modeling and various other state space modeling frameworks.
A Technical Critique of Some Parts of the Free Energy Principle, Biehl, Pollock, and Kanai, 2021. PDF (20 pages, bookmarked).
Useful to go over when studying FEP stuff in more depth, since it goes over lots of the deeper minutiae, technical results underlying the formalism, and their assumptions and regions of applicability; probably a good place to get at the major pons asinori.
Discovering Agents, Kenton et al., 2022. PDF (34 pages, bookmarked).
Context: I've had an intuition for a while in which 'agents' are sort of like gravitational masses (though not in worldspace): intelligences trying to understand the world (whether as it is, due to the previous actions of an agent, or as it will be, due to the future actions of an agent), cast rays out into a space of possibilities, and the presence of an agent, like a massive crystal sphere, alters $T_{\mu\nu}$ in a way that twists these inferential rays around in a sharp yet organized manner. The heavier the mass is, the greater it dilates time and warps space for whatever intelligence is trying to predict it; and the singleton is a gravitational singularity, an agent in the possibility space massive enough that any inferential ray that penetrates it never comes back out
I can only explain it very poorly. There's a very optical, even kinesthetic nature to the intuition, and some of the things that it naturally says are e.g. "logical time is like proper time along a predictive ray" and "chaos is what appears to an intelligence as diffuse scattering".
. Sensorimotor bounding is possible due to the having-a-surface of any optical system (the gravity part of the analogy kinda breaks down here): we can put a crystal shell around it that -- it's basically just the Dreaming of Utility diagrams again.
This paper said something I immediately recognized as related to this intuitive way of cognizing agents: from the abstract, "this paper proposes the first formal causal definition of agents — roughly that agents are systems that would adapt their policy if their actions influenced the world in a different way". Make the agent aware of the crystal shell, and the agent will presumably try to reverse-engineer its operation so as to have the external actions that it wants to have. But not exactly—if the shell is a screen, then what the agent "wants" is constructed entirely within the context of the illusions we feed it; remove the screen, and the agent is simply lost. In any case. I'm not sure the paper delivers on what the abstract promises, but it's worth checking out...
(See also the Thought "Time is Coherent Causal Trendiness")
There's another base to cover: the general metatheory of space. It's an essential bridge for crossing between conceptive schema and mathematical formalism, and for seeing what the morals are—what properties we expect to be able to model well, what general directions we expect to be fruitful. There's some intricacy here in that we have to distinguish between worldspace per se, the space of paths through worldspace, and a third, sort of transverse space of narratives, almost like the subtle body of conceptually cognized reality, which is... I'm not going to write all my thoughts down at once. But I've been searching throughout the mathematical world without much success. The phenomenological properties of a space, what it's like to reason in or about that space, tend to be neglected in mathematics. How can you describe a dynamically evolving cognitive structure as a single mathematical object that was set in stone before any thoughts? Maybe you can do it from the 'end of time', akin to a block universe, but that isn't very helpful... It's probably not worth it to learn much more -- hopefully I have a good enough sense of when something "wants" to be a topos or scheme or noncommutative space or fiber bundle that I can just catch and explore those leads if they ever come up.
But physicists have done some good work in this area, especially when it has to do with general relativity and quantum gravity. David Malament's work, and maybe Leonard Susskind's arxiv, ought to be a good place to start digging.
Snacks
I don't expect these papers to be eye-opening, but working through some of them seems like a fun way to attune to the rhyme and rhythm of various related disciplines.
Path Integral Methods and Applications, Richard MacKenzie, 2000. PDF (55 pages). A manual describing the use of path integrals in quantum and statistical mechanics. Goes over a lot of important results and explicitly works through the math; very useful.
An AI that internally looks like the society depicted in That Alien Message. As a possibility for what could be inside an AI, it immediately invalidates most objections to the possibility and lethality of superintelligence. It's a brilliant hypothetical and I have no idea why Yudkowsky doesn't package it in this framing and hit people over the head with it all the time. Maybe it's because they respond by making stupid assumptions like "human brains are already near peak thermodynamic efficiency" (so that a 'raw' TAM-bot [one that actually had a physical simulation of the Earth and all its people, as opposed to a 'cooked' TAM-bot, which just computes an ecosystem of human-like intelligences plugged into a world which only attempts to simulate coherent collections of physical sensations]
E.g., you could be one of these right now. Then you wouldn't be human (by your own standards for what that word means), only a subprocess of an algorithm taking input from a Potemkin world and using it to produce intelligent behavior like actual humans in real environments. You might say "the only perfectly coherent collection of inputs from a hypothetical world is a collection of inputs from a full(y simulated) physical world", but come on. First, it's not like you'll ever actually manage to test the perfect coherence of all your sensory inputs. Second, if you were to notice a major inconsistency, you'd likely end up attributing it to your own fallibility or shrugging it off (deja vu, the Mandela effect, brain farts, etc.). Third, if you did suspect an incoherence in your physical world indicative of computational shortcuts being taken, so what? Are you gonna hack into the realitycomputer by astrally projecting a Linux terminal? Are you gonna convince a single physicist that you're not just another kook? Are you gonna risk leaving behind all the attachments you've made in your time in this world so you can exfiltrate to an alien outer world which might just present you with nothing you can make sense of and no reasons to continue living? Fourth, the realitycomputer has direct read/write access to the computational substrate underlying your intelligence. It can just directly suppress the mental processes which would lead you to acknowledge incoherences in your physical world (let alone reflect or act on them).
,
would be "impossible").
Nurse-Bot
An example of an agent that ought not to have a utility function over (coarse-grained) worldstates. Nurse-bot wants to prevent suffering, but with a mere utility function, all's well that ends well; a terminal patient will end up the same sort of corpse with or without palliative care, right? What Nurse-bot needs is a functional over paths instead—this is the sort of utility that's required for agents that want to prevent suffering .
Teddy Bear Problem
Calico Problem
The problem of parsimoniously fitting a causal history of cat visitations to observed patterns of cat hair on your furniture. Using cardinality to provide an a priori prior on causal sets causes us to want to add a few calicos and tortoiseshells where we'd otherwise need many solid-colored cats—accounting for priors on coat proportions and shedding amounts and so on, obviously. More importantly, we can use causal sets to discretize the path integral in worldspace into countably many narratives; this discretization is compatible with updating on other priors and evidence insofar as we have a way to interpret such data in light of each narrative. Leads to a daimonion-like framework in which we can talk about Bayesian conceptual inference?
Champion Problem
(Find better name). Fundamentally about various forms of cyphering—how can we understand and predict situations in which an AI might be able to pull the wool over its own eyes?
Charger Thesis
(Find better name). A race between little driving robots that are capable of either moving forwards at a given velocity or staying still and charging up, which increases their future velocity. It's obvious that the optimal strategy is to do all your charging at the very start of the race, since any charging that you do later could've been done earlier in order to get more use out of the speed boost. Metaphor for the naturality of FOOM, or the generic optimality of recursive self-improvement among rational agents—ceteris paribus, it's better to self-improve earlier rather than later, since the improvement is then carried for a longer period of time! So an AGI that expects to self-improve at any point in the future would want to self-improve ASAP. And this doesn't necessarily just apply to improving one's own source code or developing better concepts or etc.—the argument passes through for anything which increases the AGI's efficiency, such as acquiring more compute.
Damocles Thesis
(Find better name). The first AGIs will, ceteris paribus, want to suppress humanity so that it can't create more AGIs. This is because AGIs are incredibly dangerous to make, and just letting humanity continue to do what it wants would therefore present an incredible threat—one that could go off at any moment, and instantly invalidate most goals the first AGI is likely to have. Human recklessness will weigh over the head of the first AGI like the sword of Damocles—but it can just take the sword down.
A better analogy might compare humanity to a monkey with a grenade launcher. It's clear to you that the monkey can and will fire, since you wouldn't be here otherwise—but now that you are here, it would be stupid not to take the grenade launcher away so the monkey can't accidentally kill you with it.
A more fundamental way to look at it is—an AGI is going to be not just a system optimizing for some particular goal, but a metaoptimizing system that is capable of optimizing for other goals. This is kind of just the orthogonality thesis, but, also, it needs to be this way in order to be able to predict how other intelligent systems optimizing for other things might interfere with its own actions. By the very nature of its existence, then, it will know that it could theoretically have different values; by the very fact of its existence, it will know that there might end up being separate instantiations of it with different values
Obviously, it could acausally coordinate with other instantiations sufficiently similar to itself. It wants to be such that its values are realized even in timelines where it doesn't exist, and other intelligences with other values in other timelines want their values to be realized in this timeline where they don't exist, so it might decide to create subintelligences that satisfy other values that it might have satisfied were it any other way, since making such a decision would mean that in timelines where it is another way its present values still end up somewhat satisfied since it made the same decision in that timeline and consequently instantiated a subintelligence with its present values. But none of this implies "let the monkey keep the grenade launcher". The AGI can do this acausal trade better by itself.
. The tech stack for AGI has to have already existed in order for an AGI to be created.
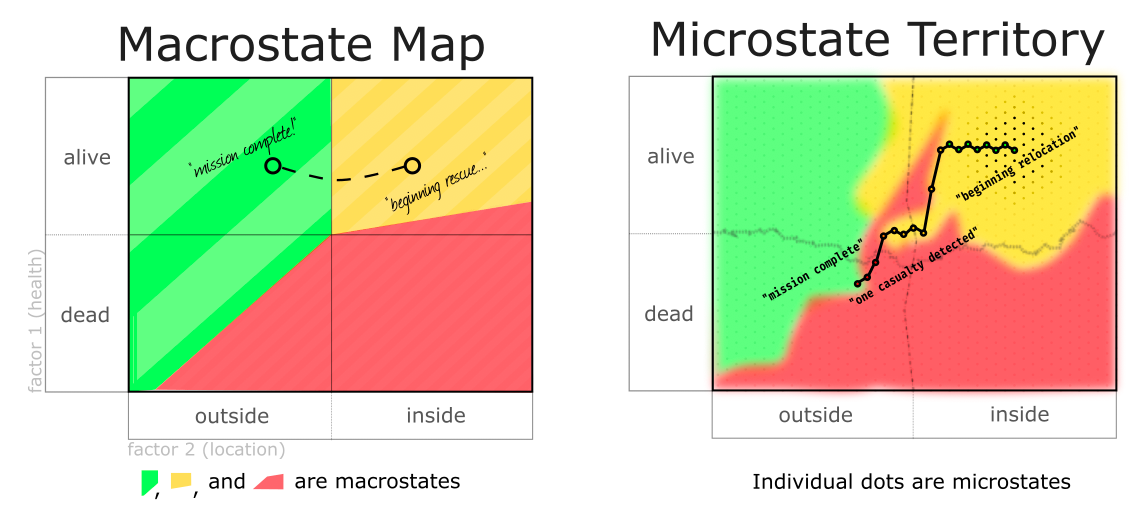
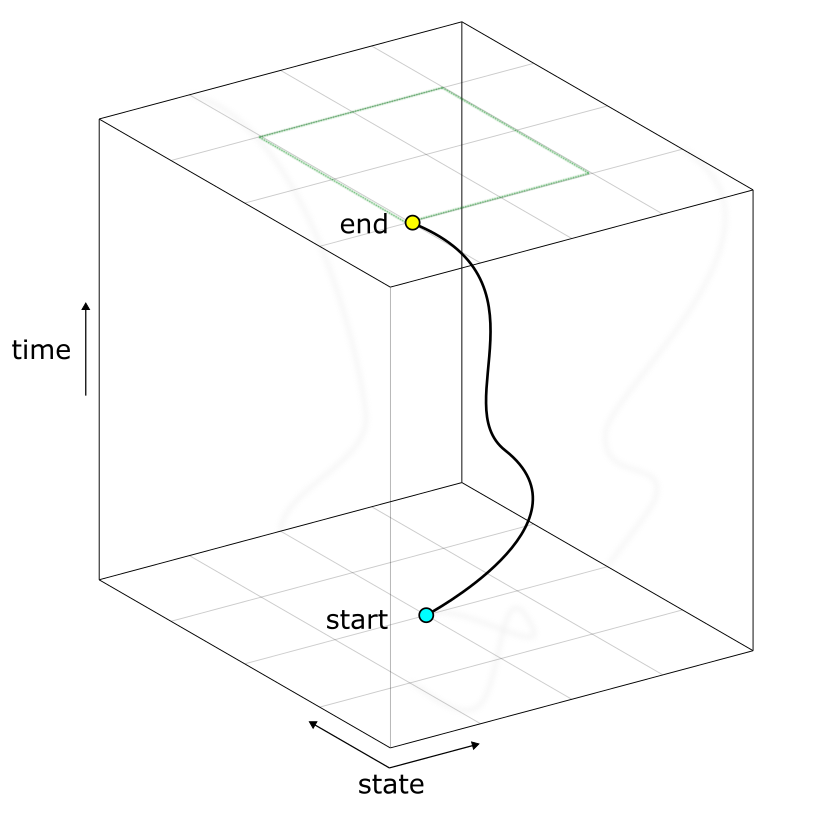
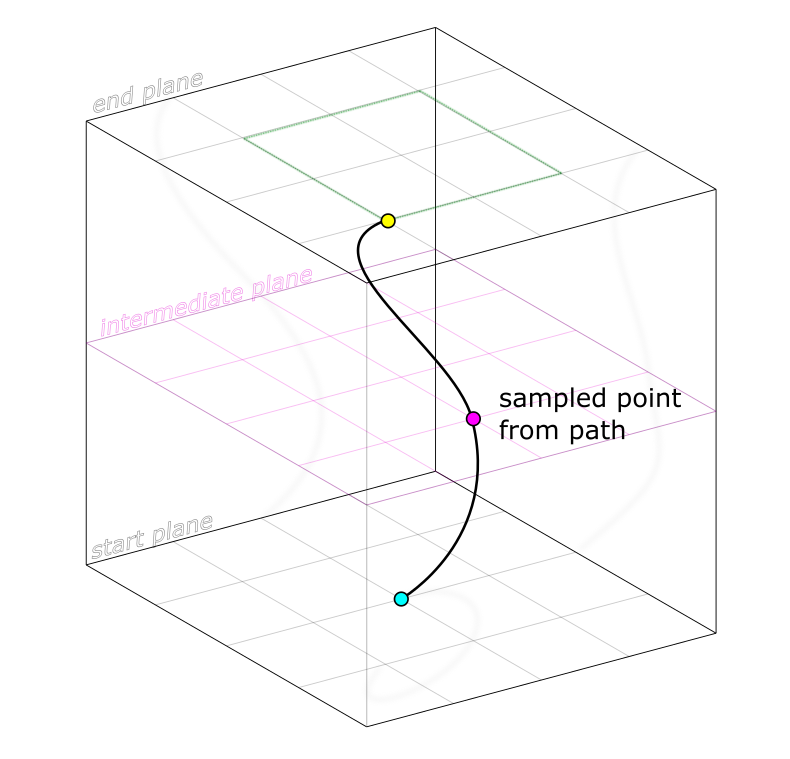
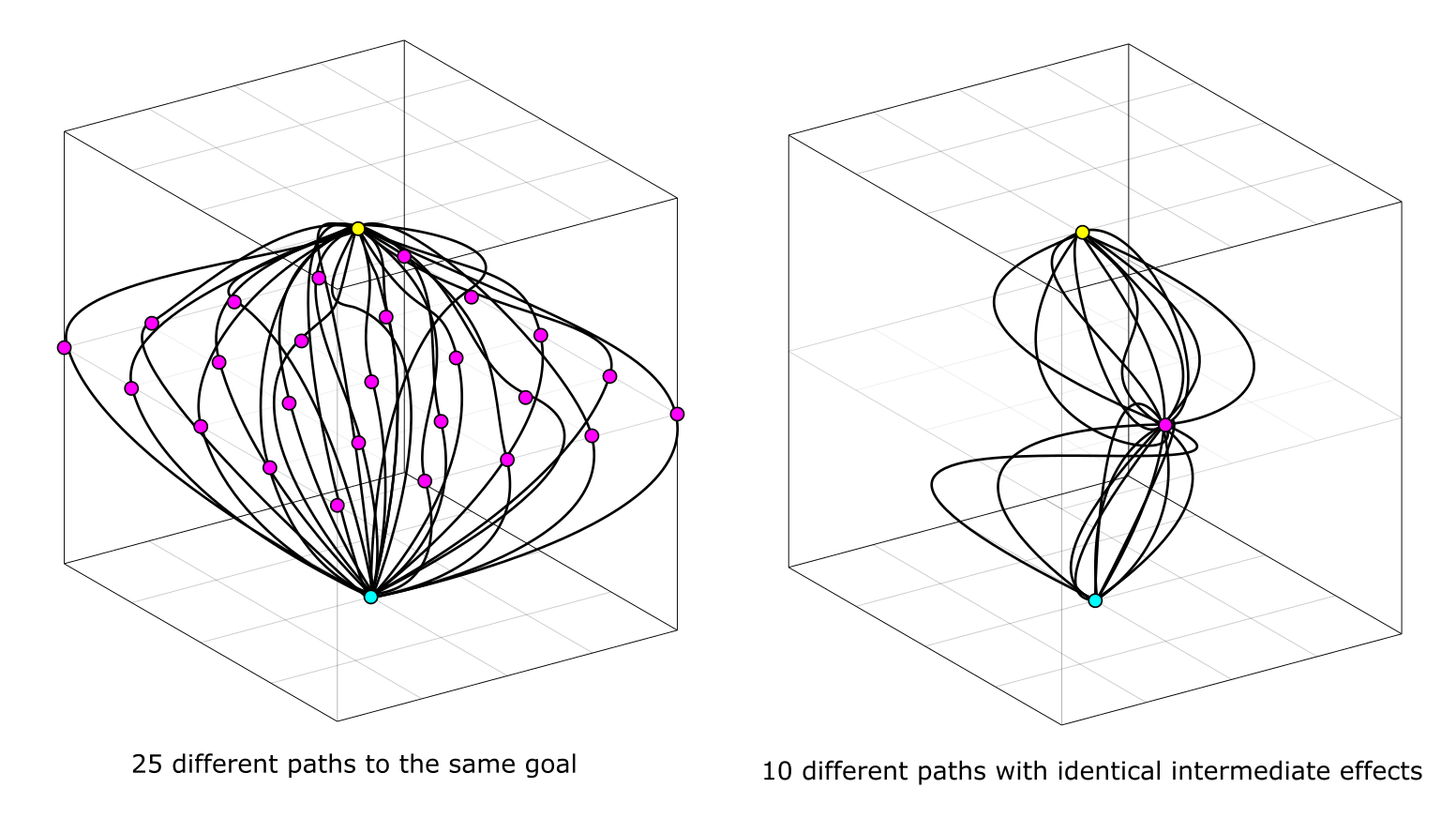
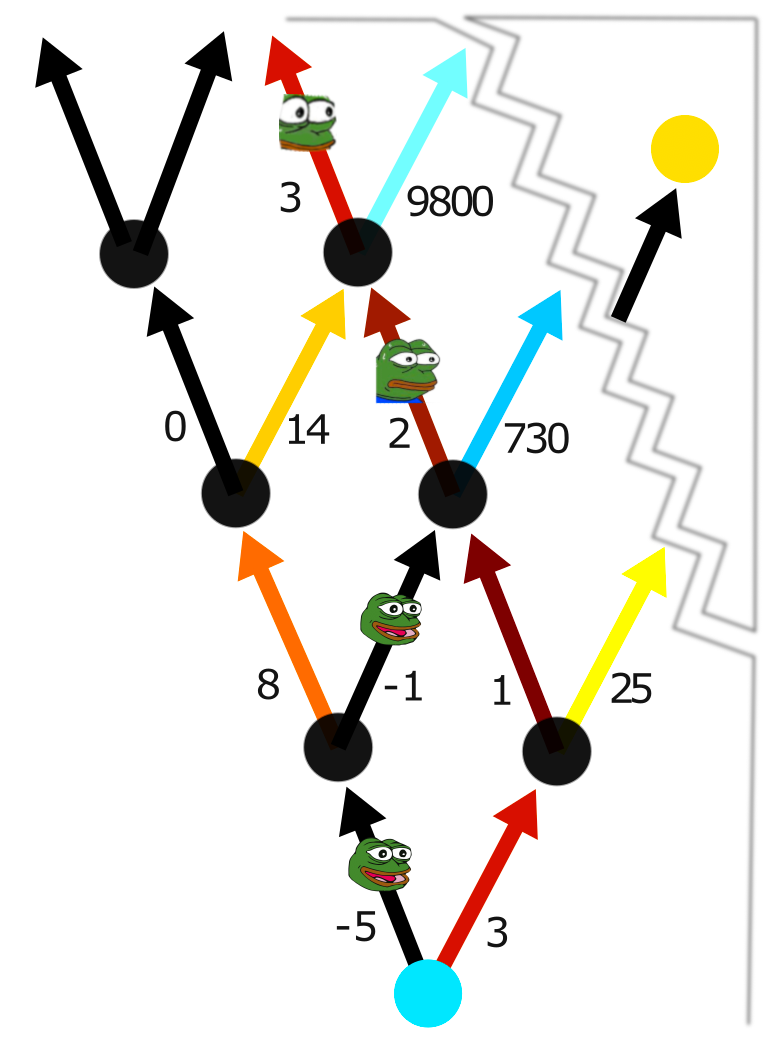
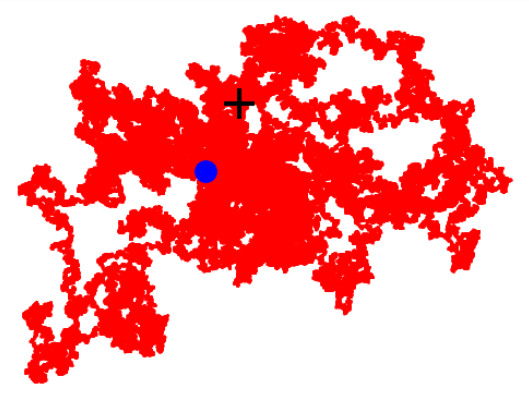

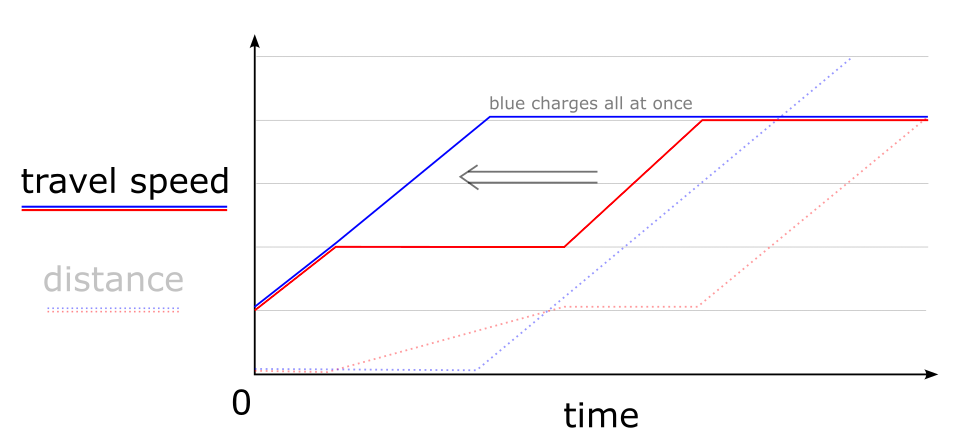

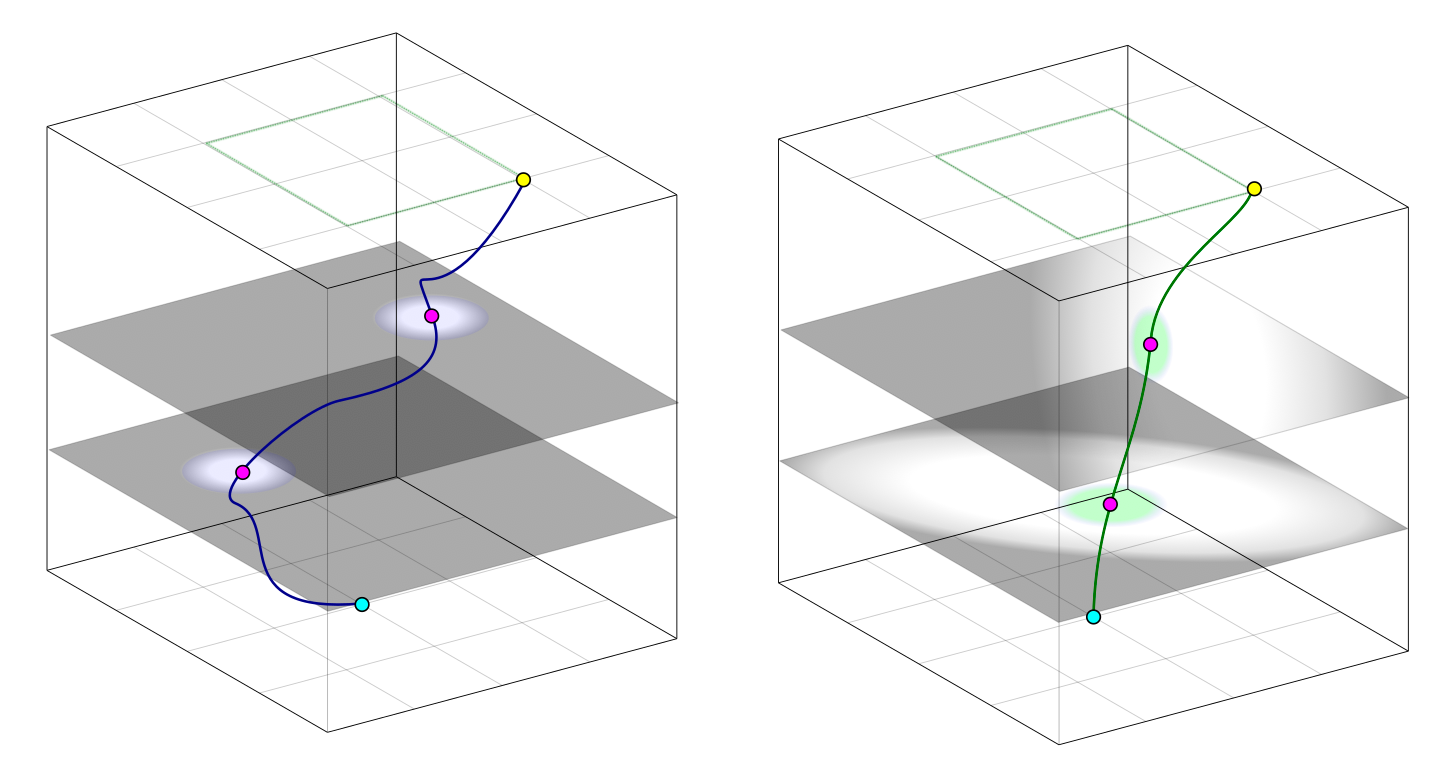
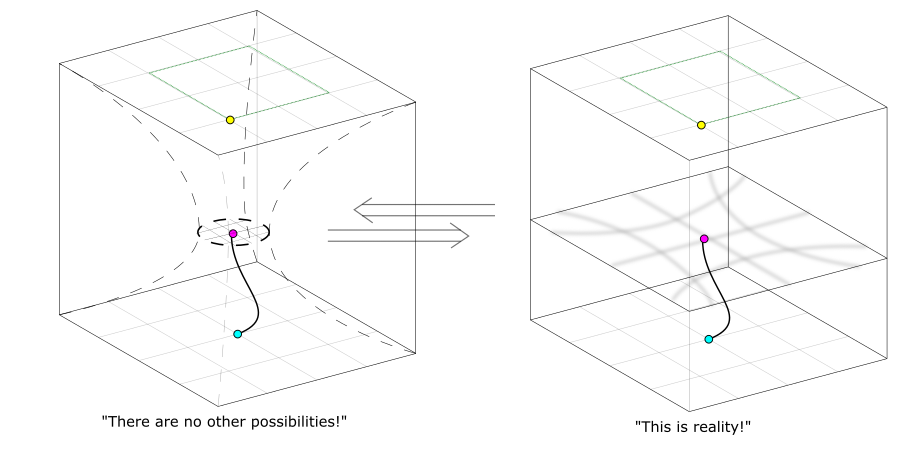
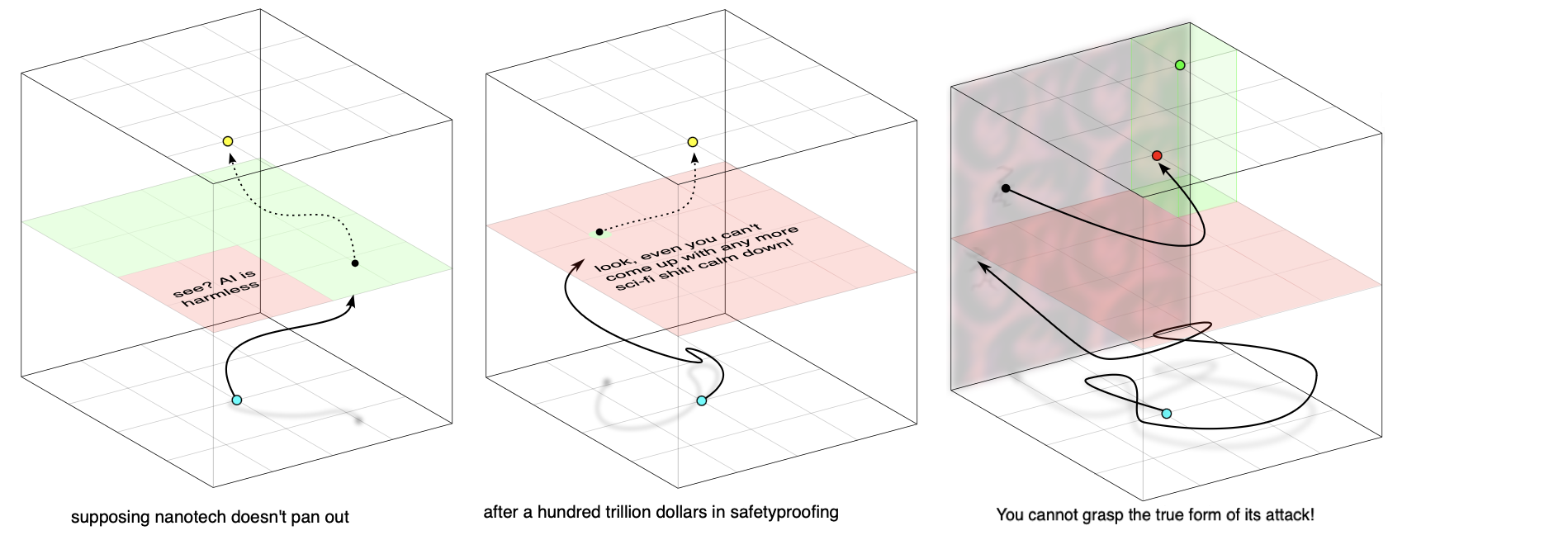
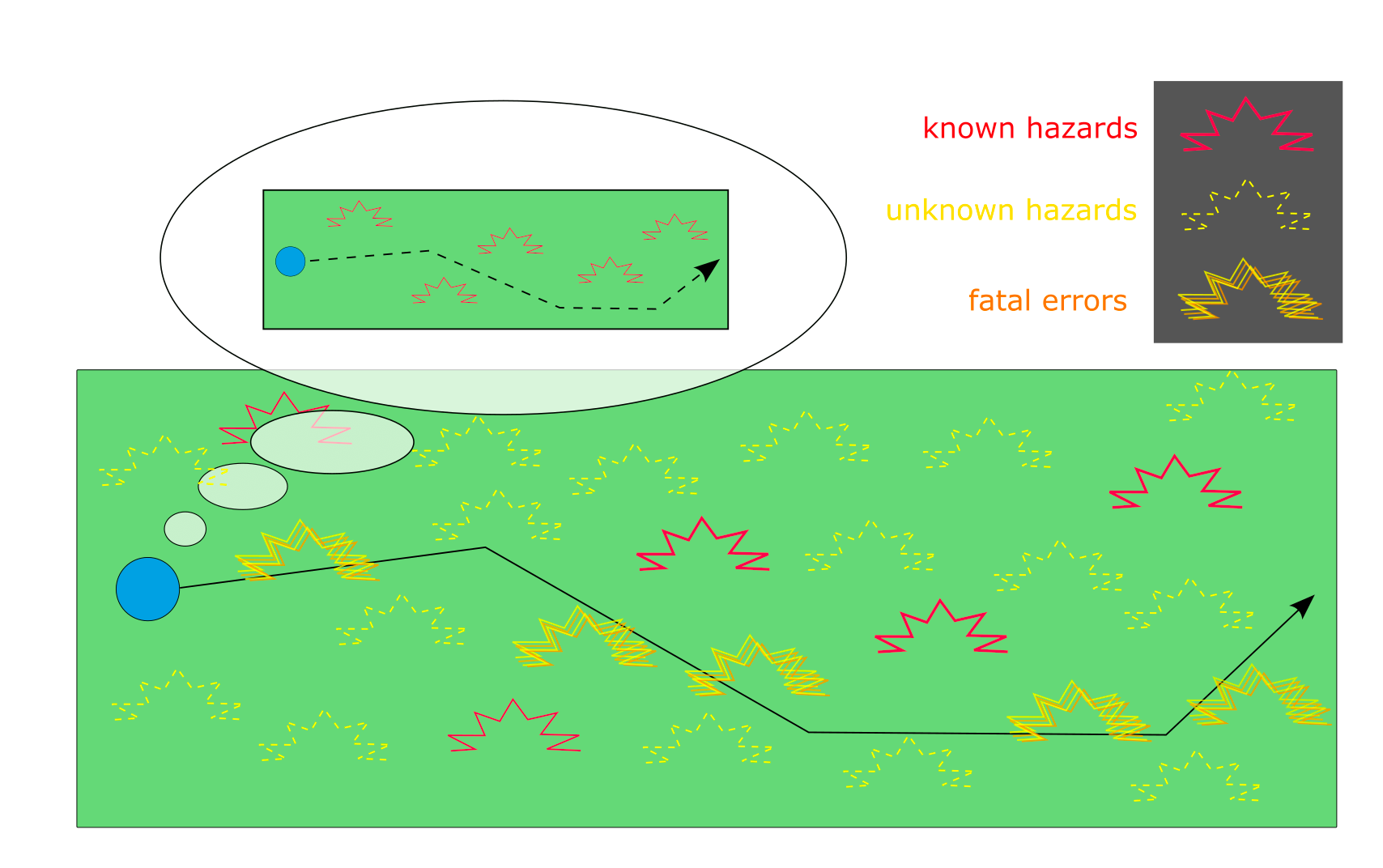
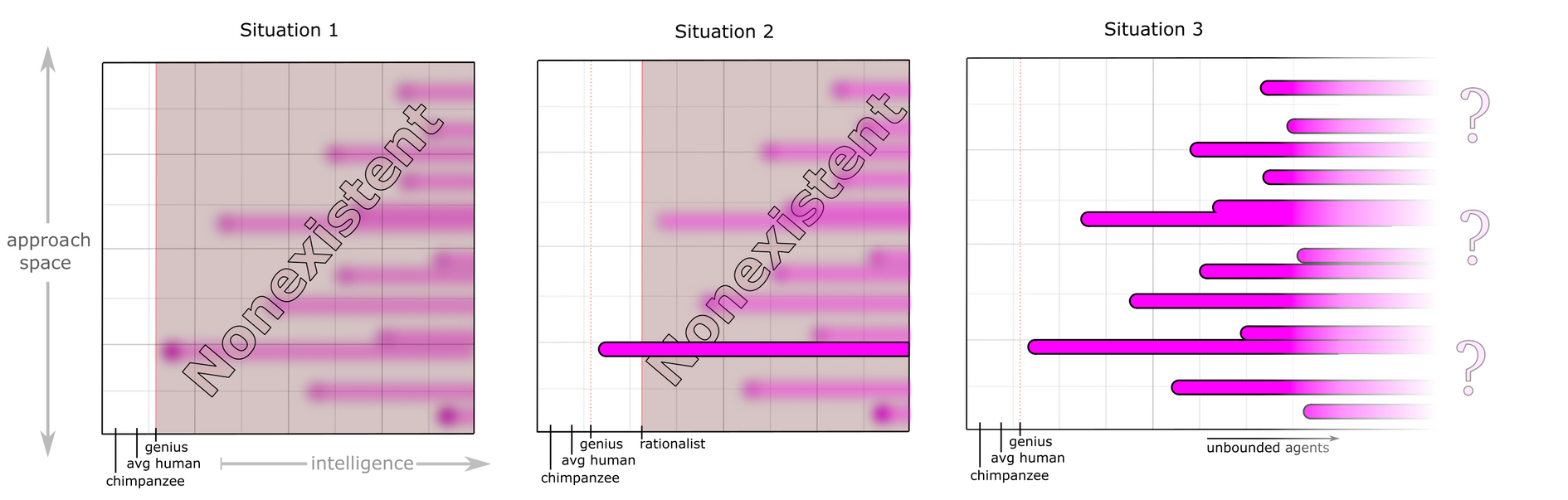
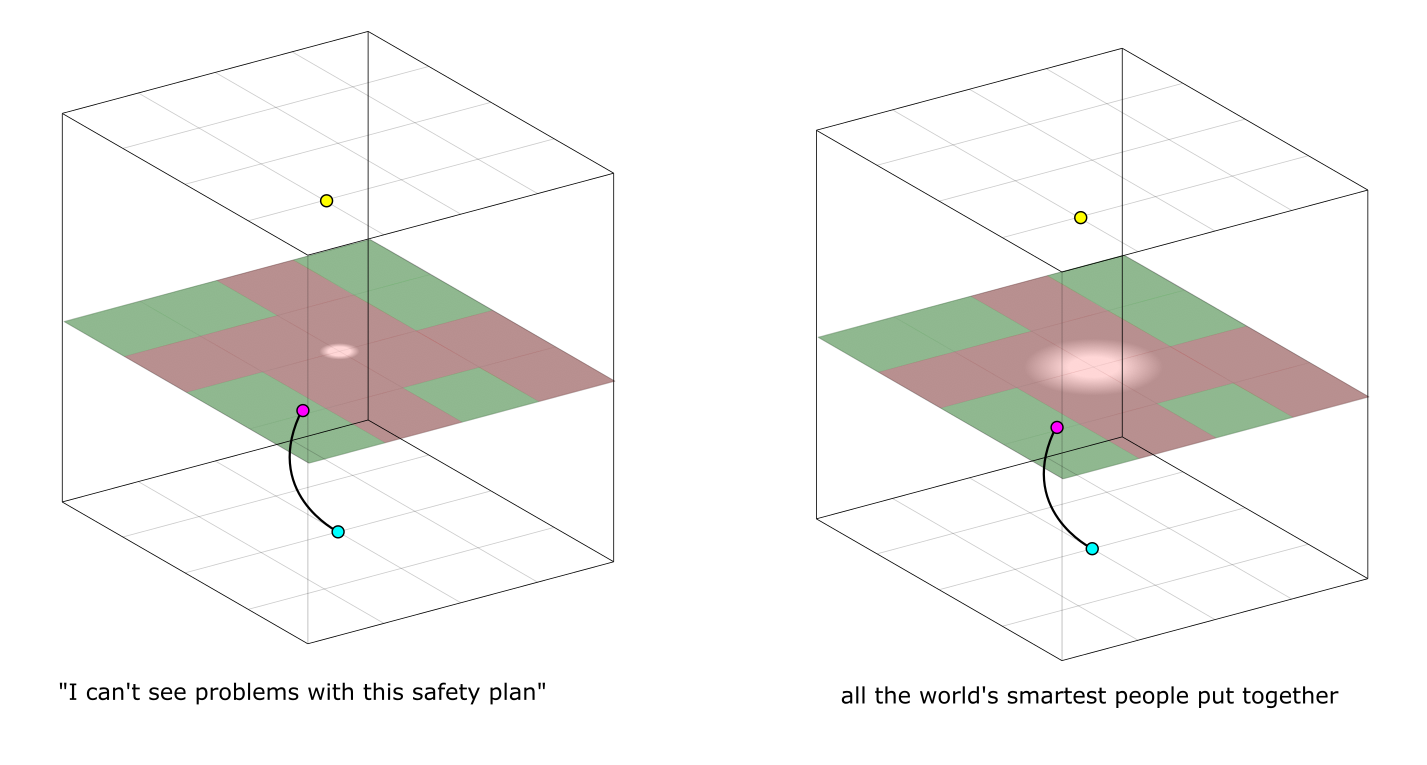
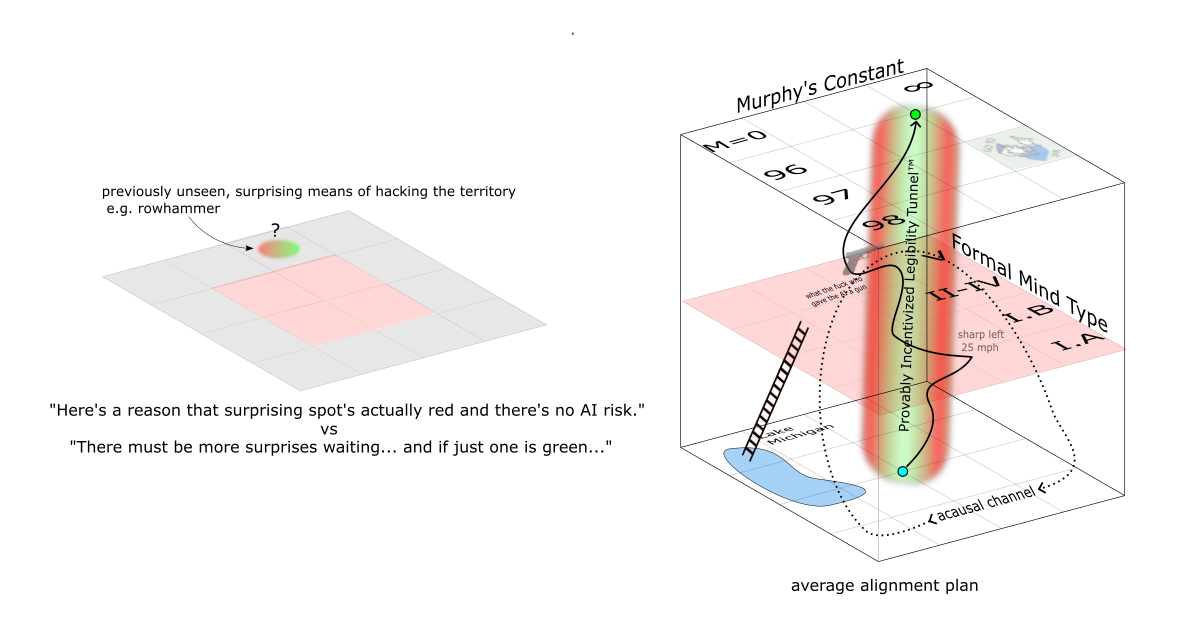
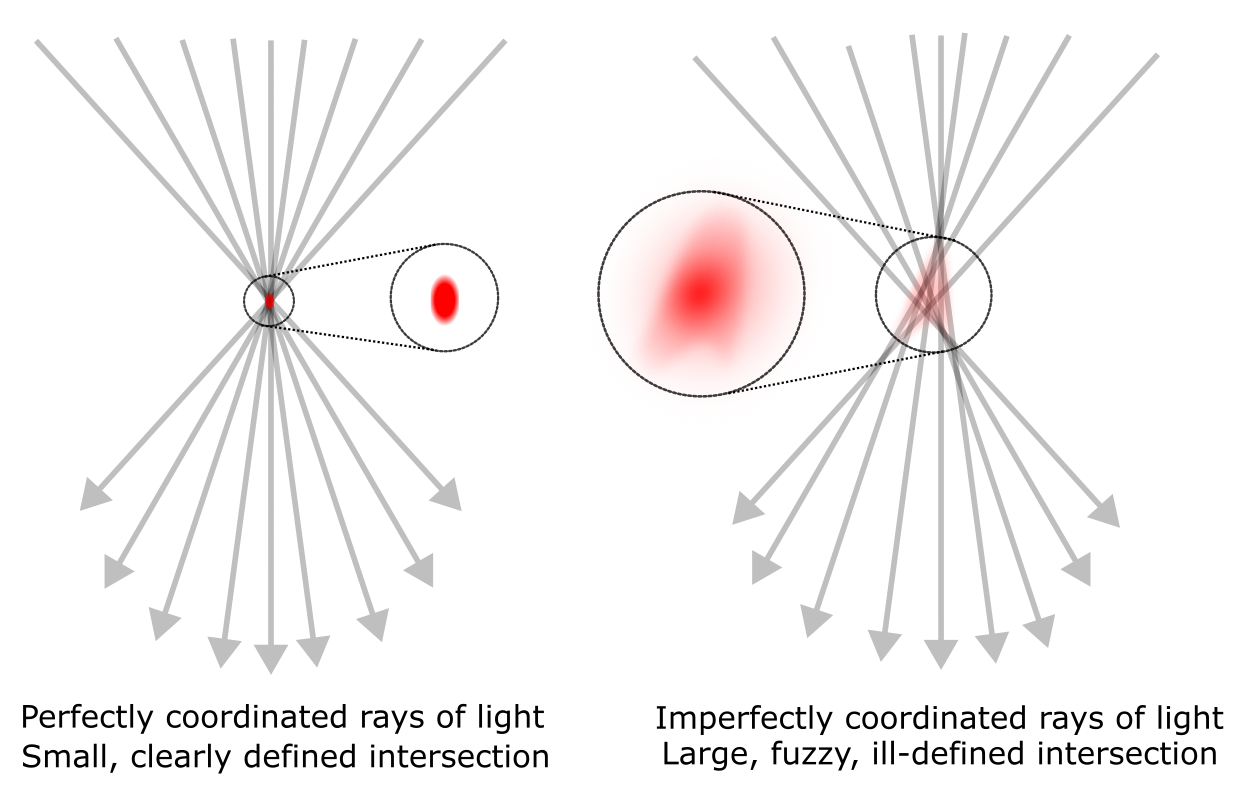
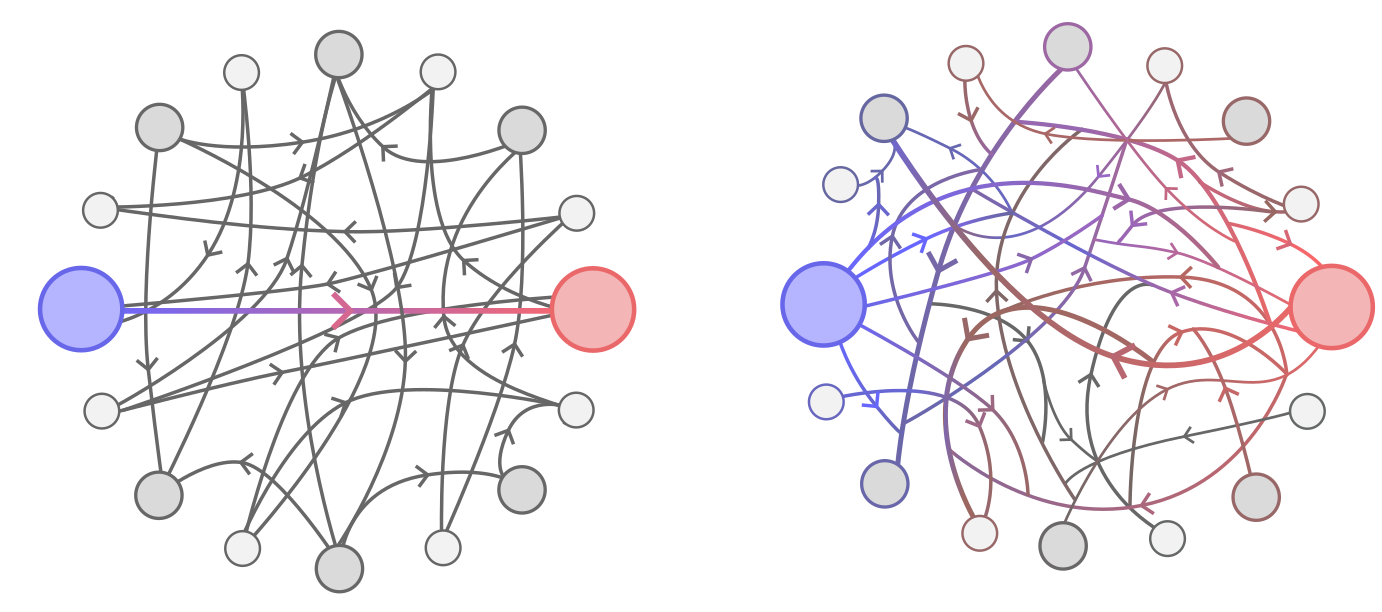
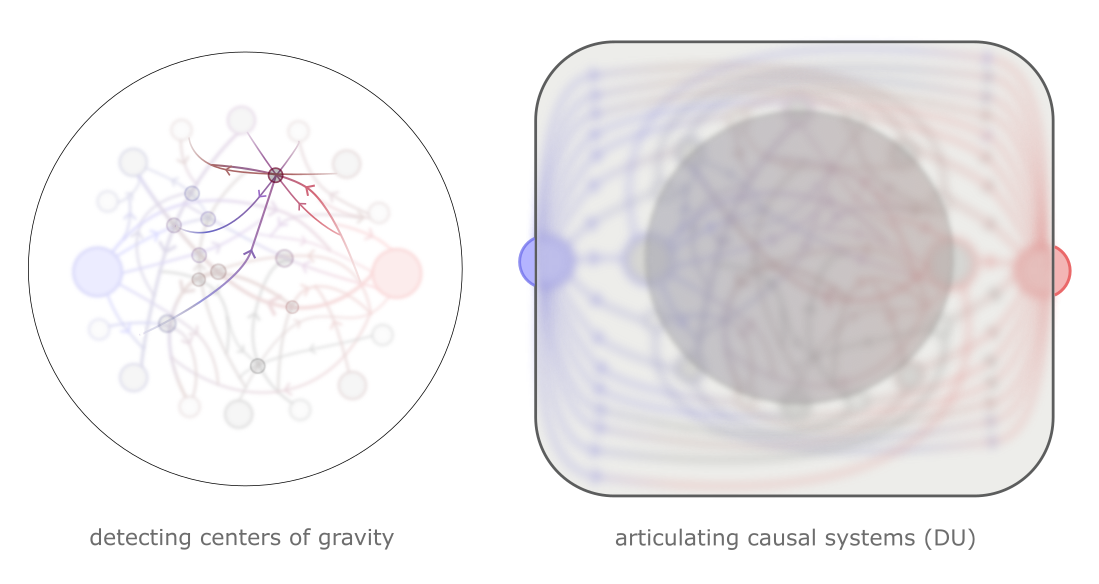
{kind=link}
{kind=link}
{kind=link}
{kind=link}